El artículo explica la metodología bayesiana para crear sistemas educativos adaptativos: cada pregunta se elige según sus respuestas anteriores, combinando el teorema de Bayes, la teoría de respuesta al ítem y la entropía de Shannon. A diferencia de los test clásicos, no exige datos de miles de alumnos ni un equipo de psicometría, sino un protocolo que cualquier docente puede ejecutar con una inteligencia artificial, ilustrado con un itinerario y un laboratorio.
OpenWorksheets es una aplicación web libre para crear fichas interactivas autocorregibles. Funciona en el navegador, sin requerir cuentas ni servidores. Permite diseñar actividades desde PDFs, imágenes, hojas en blanco o mediante inteligencia artificial. Ofrece múltiples respuestas, incluyendo fórmulas matemáticas y grabaciones de voz. Los docentes pueden compartir las fichas mediante enlaces o integrarlas en Moodle, y evaluar entregas cifradas del alumnado, garantizando así la total privacidad y control sobre sus materiales educativos.
El artículo sostiene que, ante la IA, el objetivo no es detectar su uso sino diseñar actividades donde el aprendizaje deje huellas observables. Propone graduar su uso con el marco MIAE y reunir evidencias que cumplan siete características: trazabilidad, contextualización, oralidad, presencialidad, materialidad, triangulación y transparencia. La clave está en distinguir entre usar la IA como apoyo o delegar en ella la tarea, manteniendo al alumnado dentro del proceso.
Los recursos adaptativos cambian según las respuestas del alumno, mejorando los modelos lineales. Con inteligencia artificial y vibe coding, cualquier docente puede crearlos. El sistema emplea la inferencia bayesiana para actualizar el diagnóstico tras cada interacción. Selecciona la siguiente actividad buscando reducir la incertidumbre, medida mediante la entropía de Shannon, democratizando así la personalización del aprendizaje.
METAC es un repertorio web abierto que ayuda al profesorado a localizar, comprender, relacionar y aplicar diversos recursos metodológicos en el aula. Evolucionó desde las metodologías activas iniciales para incluir también los marcos educativos y el aprendizaje cooperativo, organizados sistemáticamente por bloques y ámbitos. Además, integra un asistente de inteligencia artificial en NotebookLM para buscar propuestas didácticas mediante lenguaje natural
Este artículo presenta tres utilidades que amplían las posibilidades de eXeLearning. EdEX permite crear y modificar estilos visuales de los proyectos. eXeConvert facilita convertir entre formatos como ELPX, DOCX, Markdown o PDF, manteniendo la estructura del contenido. Visor Web-ZIP ofrece una forma sencilla de publicar y compartir recursos educativos desde servicios en la nube mediante enlaces accesibles desde cualquier navegador, sin necesidad de instalar software adicional. También admite proyectos exportados en ZIP.
Visor Web-ZIP facilita la publicación de recursos educativos en formato HTML, creados mediante IA o software específico, superando las limitaciones de plataformas tradicionales. Esta herramienta genera enlaces permanentes visualizables desde archivos ZIP alojados en servicios nube como Google Drive. Ideal para webs estáticas, simplifica el proceso frente a servidores dedicados y cuenta con un gestor de recursos que optimiza el almacenamiento local del navegador eliminando archivos antiguos automáticamente.
El vibe coding educativo es un enfoque que usa asistentes de inteligencia artificial (IA) para que los docentes creen recursos digitales, priorizando la intención pedagógica sobre el dominio exhaustivo del código. Este método sencillo reduce la barrera de entrada y el tiempo de resultados. Las herramientas se categorizan en vía web (para prototipado rápido) y locales (instaladas, para proyectos más estables). La comunidad docente facilita su adopción y el intercambio.
La segunda parte de «Ilustración científica con Gemini» detalla cómo usar fotografías propias para crear materiales educativos personalizados. Gemini transforma las imágenes en dibujos a lápiz o esquemas, permitiendo añadir etiquetas y texto. Esto es útil en áreas como ciencias naturales (esquemas de lupas binoculares), física (dibujos técnicos de poleas), matemáticas (diagramas de ángulos), geología (identificación de estratos) y biología (dibujos de insectos).
La integración de Nano Banana Pro en Gemini ofrece el primer avance real para ilustraciones científicas rigurosas en la docencia. La herramienta aún no es autónoma, y los errores aparecen continuamente, lo que exige supervisión y guiado docente. Para asegurar la calidad, es fundamental la corrección iterativa de fallos o el uso de imágenes de referencia. Además, se recomienda la validación externa usando otras IA, como ChatGPT o Claude, para auditar la imagen antes de su uso.
El Marco MIAE (v.2 revisada) clarifica la integración de la IA generativa en educación. Se refina la escala, desde la persona creando sola hasta la IA generando autónomamente bajo supervisión humana. Se detalla cuándo la IA reformula contenido existente o planifica ideas, y se distingue la creación de borradores de la co-creación mediante diálogo. El marco enfatiza el rol activo de la persona, garantizando el uso ético de la IA y la integridad académica en todas las tareas educativas.
Un agente educativo es un asistente digital configurado con IA para apoyar tareas pedagógicas. Su función es interpretar instrucciones, mantener un contexto y producir resultados específicos. Existen distintos tipos: planificador, corrector, documental, creador de recursos y tutor. Plataformas como Gemini, NotebookLM, Grok, Le Chat, ChatGPT y Perplexity permiten crearlos sin conocimientos técnicos. Estos agentes amplían las posibilidades docentes al automatizar tareas y personalizar apoyos, sin sustituir al profesorado
Este artículo guía a docentes sin programación en la creación de herramientas educativas con IA, usando lenguaje natural (Vibe Coding). Explora chatbots como Gemini y ChatGPT para generar juegos, fichas interactivas o formularios en HTML. Detalla la selección del chatbot, la comunicación con prompts, la depuración de errores y la publicación de recursos. La IA amplía las posibilidades didácticas, potenciando la creatividad y adaptando materiales al contexto de aprendizaje
Los docentes que crean materiales digitales deben elegir licencias claras para facilitar su uso y colaboración. Los contenidos educativos se recomiendan con CC BY-SA, que asegura atribución y reciprocidad, mientras que el código puede protegerse con GPL v3, fomentando mejoras compartidas. Existen otras opciones como CC BY, MIT o Apache 2.0, según los objetivos. Adoptar licencias adecuadas fortalece la comunidad educativa y garantiza que los recursos permanezcan abiertos y accesibles
La segunda parte de la guía explica cómo sacar mayor provecho de las consolas de IA (CLI) al trabajar directamente en el ordenador sin depender de la web. Describe ventajas como ejecutar operaciones masivas, usar múltiples archivos y aprovechar archivos de instrucciones en Markdown para personalizar el comportamiento. También detalla cómo identificar y cambiar modelos, iniciar la consola con prompts y utilizar atajos y comandos útiles que facilitan la programación y la automatización.
La primera parte de la guía enseña a docentes cómo usar la IA (Gemini, ChatGPT, Qwen y Claude) desde la línea de comandos, una interfaz que permite interactuar directamente con el ordenador. Se detallan pros y contras frente a las versiones web, destacando la capacidad de manipular archivos y automatizar tareas. También se explican los conceptos básicos, como la instalación y los comandos.
El artículo explica qué son los prompts en formato JSON y por qué son útiles al trabajar con inteligencia artificial. Describe su estructura basada en claves y valores, sus ventajas como claridad, reutilización y compatibilidad, y destaca su aplicación en educación para generar contenidos precisos. Señala que no es necesario escribirlos manualmente, sino saber pedirlos y conservarlos. Incluye ejemplos prácticos y recomienda usar editores JSON para facilitar su edición y uso recurrente.
El artículo analiza la capacidad de distintos chatbots para resolver cálculos matemáticos. Destaca que ChatGPT y Claude son los más precisos, especialmente si se les indica usar programación. También se explica cómo convertir documentos a texto plano (Markdown) para mejorar su comprensión por parte de la IA. Además, se recomienda usar LaTeX para fórmulas complejas y se mencionan herramientas útiles para integrar resultados en procesadores de texto. Ideal para docentes que usan IA en educación.
Este artículo explica cómo desarrollar un chatbot educativo usando Gemini con canvas. El ejemplo muestra un tutor socrático que analiza textos y genera preguntas para verificar la comprensión del estudiante. Se requiere el modelo 2.5 Pro, definir objetivos claros y crear un prompt detallado. Incluye consejos para depuración, compartir el programa y solucionar errores comunes mediante la técnica «vibe coding».
Este artículo explica cómo crear una aplicación HTML que recoja respuestas de un formulario (nombre, sugerencias y valoración de 0 a 4) y las envíe automáticamente a una hoja de cálculo de Google usando Apps Script. Se detallan los pasos para configurar la hoja, escribir el script y otorgar permisos. También se muestra cómo obtener la URL necesaria para integrarla en la aplicación. Es una guía práctica orientada a aplicaciones educativas interactivas.
El Asistente de Estudio Inteligente Multilingüe facilita el aprendizaje adaptando automáticamente su interfaz al idioma del navegador. Permite fijar edad e idioma de interacción, cargar textos o imágenes y, mediante IA, generar resúmenes, FAQ, flashcards y mapas conceptuales descargables. Incluye práctica guiada con diversos tipos de preguntas, chat enfocado al contenido y un informe de progreso. Cada sesión es única y personalizable, potenciando comprensión y autonomía eficaz.
«El profesor que no existía» es una novela publicada el 14 de mayo de 2025 por Juan José de Haro, creada en colaboración con Claude, una IA de Anthropic. Presenta tres dimensiones: la narrativa sobre Gabriel Vega (un profesor digital en un instituto), una banda sonora que acompaña cada capítulo, y una dimensión interactiva donde el personaje existe como IA en ja.cat/gabrielvega. La obra cuestiona los límites entre lo real y lo simulado, la memoria, la identidad y el futuro de la enseñanza.
Aprende a activar chatbots de IA (Grok, ChatGPT, etc.) en recursos educativos (HTML, Moodle, etc.). Pasa prompts vía URL para que la IA ejecute instrucciones, incluyendo datos del usuario. Técnica: Vibe Coding
El diseño experimental con inteligencia artificial optimiza la aplicación del método científico, facilitando la formulación de hipótesis, la estructuración de variables y el análisis de resultados. La IA mejora la precisión y eficiencia de los experimentos, fomentando el pensamiento crítico y la replicabilidad en la enseñanza. Esta herramienta transforma la investigación educativa y científica, asegurando rigor metodológico.
El método de los 3 expertos utiliza inteligencia artificial para generar debates entre personajes con distintas perspectivas. Esta técnica fomenta el pensamiento crítico en el aula, permitiendo a los estudiantes analizar, contrastar y formular sus propias opiniones. Su aplicación en diversas materias fortalece la argumentación, el aprendizaje activo y la evaluación de información con mayor profundidad.
Este artículo describe los fundamentos básicos de la metodología utilizada para crear recursos educativos que se adaptan a las respuestas del alumno. Puedes ver ejemplos aquí:
Laboratorio de combinatoria (sección: Práctica – Resuelve problemas). Ejercicios de combinatoria para aprender y comprobar la multidimensionalidad del modelo, donde no solo se evalúan conocimientos, sino también habilidades transversales de forma adaptativa.
¿Cómo comparas los decimales? Un recurso adaptativo que no solo comprueba si el alumno acierta o falla al comparar decimales, sino que intenta averiguar qué tipos de errores conceptuales hay detrás de sus respuestas. Es un ejemplo de evaluación de ítems no ordenados (cada error conceptual es independiente de los otros).
¿Frío o caliente? Parte de dos errores comunes en la concepción del calor y determina si se tiene uno de los dos o ninguno.
Si lo que quieres es implantarlo mediante IA en algún recurso nuevo o que ya tengas hecho, en la web Recursos educativos adaptativos tienes un archivo para adjuntar a la IA de forma que sepa cómo debe actuar para crear una página web con el recurso adaptativo y, aunque no es necesario, también hay una guía para el docente.
Planteamiento general de la metodología
Una actividad fija, sea una prueba, un ejercicio o cualquier otro recurso, plantea las mismas preguntas, en el mismo orden, a todo el alumnado, sin tener en cuenta su nivel de partida: mide, pero no se ajusta a quien la responde. La metodología que se describe en este artículo resuelve esa limitación haciendo que cada pregunta dependa de las respuestas anteriores dadas por el alumno.
El teorema de Bayes, la teoría de respuesta al ítem y la entropía de Shannon, que se utilizan, ya existen por separado desde hace décadas en la literatura de medición educativa; lo que aporta esta metodología es la forma de combinarlos y, sobre todo, que todo el procedimiento está escrito como un protocolo reproducible que una inteligencia artificial puede ejecutar para generar un recurso nuevo en cualquier materia, sin equipo de psicometría ni datos de miles de alumnos.
Representación probabilística del estado del alumno
El sistema no calcula una nota al final del proceso, sino que mantiene una distribución de probabilidad sobre varias hipótesis de nivel del alumno, por ejemplo, tres hipótesis sobre su nivel: H1 (básico), H2 (medio) y H3 (avanzado), cada una con un valor asociado de habilidad θ (theta).
Al empezar, el sistema no sabe nada del alumno, así que reparte la probabilidad de pertenencia a un nivel en partes iguales: P(H1) = P(H2) = P(H3) = 0,33. A medida que el alumno responde preguntas, esa probabilidad se va desplazando hacia la hipótesis que mejor explica lo que está ocurriendo. Nunca hay un único número que resuma al alumno, sino una distribución completa de lo probable y lo improbable en ese momento, lo que permite representar también la duda: un alumno con un patrón de respuestas contradictorio queda reflejado como una probabilidad repartida entre varias hipótesis, en vez de forzarlo a encajar en una etiqueta.
Actualización bayesiana de las hipótesis de nivel
El mecanismo que desplaza esa probabilidad entre diferentes niveles al responder se llama actualización bayesiana, y se apoya directamente en el teorema de Bayes:
\(P(H_i \mid r)\) es la probabilidad a posteriori: la probabilidad de la hipótesis \(H_i\) (por ejemplo, «nivel avanzado») una vez conocida la respuesta r del alumno. Es el resultado que interesa, la creencia ya actualizada tras una respuesta.
\(P(H_i)\) es la probabilidad a priori: la probabilidad que se le daba a esa misma hipótesis antes de conocer la respuesta.
\(P(r \mid H_i)\) es la verosimilitud: la probabilidad de que se produjera esa respuesta concreta si la hipótesis \(H_i\) (el nivel de habilidad que se está evaluando, por ejemplo, «nivel avanzado») fuera cierta. La calcula el modelo de respuesta al ítem que se describe en la sección siguiente.
\(\sum_j P(r \mid H_j) \cdot P(H_j)\) es el término de normalización: la suma de esa misma cantidad para todas las hipótesis, que garantiza que las probabilidades finales sumen 1 y no tiene otra función que esa.
La fórmula dice que la nueva creencia sobre cada hipótesis (la probabilidad a posteriori, \(P(H_i \mid r)\)) es proporcional a dos cosas: lo bien que esa hipótesis explica la respuesta que se acaba de observar (la verosimilitud, \(P(r \mid H_i)\)) y la creencia que ya se tenía sobre ella (la probabilidad a priori, \(P(H_i)\)). Las hipótesis que hacían más probable la respuesta observada ganan peso; las que la hacían improbable lo pierden.
Ejemplo numérico del proceso de actualización
El siguiente ejemplo aplica el mecanismo a un caso concreto. Se parte de tres hipótesis con su habilidad ya fijada: H1 (θ₁ = −2, nivel básico), H2 (θ₂ = 0, nivel medio) y H3 (θ₃ = +2, nivel avanzado). El estado del alumno se representa como un vector de probabilidad P = (P(H1), P(H2), P(H3)), con un valor para cada hipótesis (el nivel al que pertenece) en ese orden y que siempre suma 1; al principio, sin ninguna respuesta todavía, ese vector es una probabilidad a priori uniforme, P = (0,33; 0,33; 0,33). Cada pregunta tiene además una dificultad b, en la misma escala que θ, que se explica con detalle en la sección siguiente: por ahora basta con saber que b = −1 corresponde a una pregunta fácil y b = 0 a una pregunta de dificultad media.
El alumno falla una pregunta fácil (dificultad b = −1). La verosimilitud de fallar es alta bajo H1 y baja bajo H3, así que el vector de probabilidad se desplaza a P = (0,81; 0,18; 0,01): la probabilidad de H1 sube a 0,81, y las de H2 y H3 bajan a 0,18 y 0,01.
El alumno acierta la siguiente pregunta, de dificultad media (b = 0). El vector pasa a P = (0,65; 0,32; 0,03): la probabilidad de H1 baja ligeramente y la de H2 sube, porque acertar una pregunta de dificultad media es más compatible con un nivel medio que con uno básico.
La figura 1 muestra esa evolución junto con la entropía de cada paso (concepto que se explica en la sección siguiente). Entre el segundo y el tercer paso, la incertidumbre aumenta en lugar de disminuir, porque el acierto en una pregunta media reparte de nuevo la probabilidad entre H1 y H2. Se trata de un comportamiento correcto del modelo, no de un error: cada respuesta aporta la evidencia que aporta y no siempre reduce la incertidumbre. Este ejemplo se limita a dos preguntas y, como se explica en el criterio de finalización más adelante, una implementación real no daría por buena la convergencia solo por cruzar los umbrales de entropía y confianza, sino que exige además un número mínimo de preguntas respondidas.
Figura 1. Actualización bayesiana de las tres hipótesis de nivel a lo largo de dos preguntas, con la entropía de cada paso.
Este cálculo se repite tras cada respuesta, de manera que la creencia sobre el alumno nunca queda congelada. Si un alumno empieza fallando, pero después encadena varios aciertos, el sistema revisa su estimación y se aleja del diagnóstico inicial: no existe un bloqueo irreversible en una categoría equivocada, algo que sí puede ocurrir en sistemas más simples que solo suben la dificultad tras un acierto y la bajan tras un fallo.
El modelo de respuesta al ítem y la dificultad de las preguntas
La verosimilitud \(P(r \mid H_i)\) que exige el teorema de Bayes no puede inventarse pregunta a pregunta y hace falta un modelo que relacione el nivel del alumno con la probabilidad de acertar una pregunta de una dificultad determinada. Esta metodología usa para ello la teoría de respuesta al ítem (TRI o, en inglés, IRT), en concreto el modelo logístico de tres parámetros (3PL), ya empleado en evaluación educativa desde los trabajos de Birnbaum en los años sesenta:
θ es el nivel del alumno en la hipótesis que se está evaluando.
\(b_q\) es la dificultad de la pregunta q: el punto en el que la probabilidad de acierto (descontado el azar) llega al 50 %.
\(a\) es la discriminación: la pendiente de la curva. Cuanto mayor es \(a\), más bruscamente distingue la pregunta entre un alumno justo por debajo y justo por encima de su dificultad.
\(c_q\) es el suelo de azar: la probabilidad mínima de acertar sin saber nada, que depende del número de opciones (0,25 en una pregunta de cuatro opciones, 0,5 en un verdadero/falso, 0 en una respuesta numérica abierta).
La figura 2 dibuja esa curva para tres preguntas de dificultad fácil, media y difícil, con a = 1,5 y c = 0,25, valores ilustrativos (el protocolo no fija a directamente: parte de una discriminación efectiva \(a_{ef} = 1.25\) y deriva a según el azar de cada pregunta). Se observa por qué una pregunta fácil es poco útil para un alumno avanzado (su probabilidad de acierto ya está pegada a 1) y por qué la zona más informativa de cada curva es la que rodea su propia dificultad, donde el resultado todavía podría ser acierto o fallo.
Figura 2. Curvas características del ítem para tres niveles de dificultad, con el suelo de azar y las tres hipótesis de nivel marcadas.
Estos valores de a, b y c no proceden de una calibración empírica con miles de respuestas reales, como ocurriría en un banco de ítems de una prueba estandarizada. Se generan a partir de valores por defecto respaldados por la literatura en TRI (Birnbaum, 1968; van der Linden y Hambleton, 1997), con a = 1,5 como punto de partida razonable, y de la estructura de cada pregunta. Es una limitación reconocida de manera explícita en la documentación técnica: son estimaciones a priori, útiles para poner en marcha el sistema, pero no medidas contrastadas con una muestra real de alumnado.
La entropía de Shannon como medida de incertidumbre
En este contexto, la incertidumbre no se refiere a una duda genérica, sino al grado en que la probabilidad sobre el nivel del alumno sigue repartida entre varias hipótesis. Si, tras algunas respuestas, las hipótesis H1, H2 y H3 tienen probabilidades parecidas, el sistema todavía no puede inclinarse con claridad por un diagnóstico. En cambio, si una de ellas concentra casi toda la probabilidad, la incertidumbre es baja, porque el estado del alumno está mucho mejor definido.
El sistema necesita cuantificar esa incertidumbre para tomar dos decisiones concretas a lo largo de la prueba. Por un lado, para decidir cuándo dejar de preguntar, es decir, cuándo la creencia sobre el nivel del alumno ya es lo bastante firme como para dar el diagnóstico por bueno, algo que se desarrolla en el criterio de finalización más adelante. Por otro, para comparar qué pregunta, de entre las disponibles, reduciría más esa incertidumbre si se planteara, que es el criterio de selección que se explica en la sección siguiente. La magnitud elegida para cuantificarla es la entropía de Shannon, tomada directamente de la teoría de la información.
$$H(p) = -\sum_{i} p_i \log_2 p_i$$
Se mide en bits. Con tres hipótesis equiprobables (0,33 cada una), la entropía es máxima: \(H = \log_2 3 \approx 1{,}58\) bits, la ignorancia total del punto de partida de la figura 1. Cuando una hipótesis concentra casi toda la probabilidad, la entropía cae hacia 0: por ejemplo, una distribución (0,95; 0,04; 0,01) tiene una entropía de solo 0,32 bits.
La entropía es preferible a mirar simplemente «cuál es la hipótesis con más probabilidad», porque distingue matices que un máximo por sí solo no recoge: dos distribuciones pueden compartir la misma hipótesis ganadora con la misma probabilidad y, sin embargo, repartir el resto de un modo muy distinto, lo que la entropía sí refleja. Por ejemplo, P = (0,80; 0,15; 0,05) y P = (0,80; 0,19; 0,01) comparten la misma hipótesis ganadora con la misma probabilidad (0,80), así que mirar solo el máximo sugeriría el mismo grado de confianza en ambos casos. Sus entropías, sin embargo, son distintas: 0,88 bits y 0,78 bits respectivamente, porque en la segunda distribución el 20 % restante está mucho más concentrado en una sola hipótesis (0,19 frente a 0,01) que en la primera (0,15 frente a 0,05). En la práctica, eso significa que la entropía captura matices de la distribución que el máximo no recoge, y por eso es la magnitud con la que el sistema mide la incertidumbre y valora cuánto la reduciría cada pregunta. Para cerrar el diagnóstico, en cambio, lo que decide es la confianza mínima de la hipótesis ganadora junto con el mínimo de preguntas: cuando el umbral de entropía se deriva de esa misma confianza, la condición de confianza ya implica la de entropía, de modo que comprobar ambas es inofensivo, pero no añade exigencia.
Selección de preguntas por ganancia esperada de información
Aquí aparece uno de los puntos donde esta metodología se aparta de la práctica habitual en los test adaptativos informatizados (CAT, por sus siglas en inglés). El criterio para elegir la siguiente pregunta es la ganancia esperada de información, es decir, cuánto se espera que baje la entropía si se hace esa pregunta, promediando los dos resultados posibles:
donde \(P(A)\) y \(P(F)\) son las probabilidades esperadas de acierto y fallo bajo la distribución actual, y \(P_{post,A}\), \(P_{post,F}\) son las probabilidades a posteriori que resultarían en cada caso. El sistema calcula esta ganancia para todas las preguntas disponibles y elige la que promete reducir más la incertidumbre, sea cual sea la respuesta.
El criterio dominante en los CAT clásicos no es este, sino la función de información del ítem (FII), basada en la información de Fisher:
La FII mide cuánta información aporta una pregunta en un punto concreto de la escala continua de habilidad θ (por ejemplo, θ = −1,5 podría corresponder a un alumno con dificultades notables, θ = 0 a uno de nivel medio y θ = +1,5 a uno con un dominio alto, pero también son válidos valores intermedios como θ = 0,7, a diferencia de las tres hipótesis discretas que maneja el enfoque bayesiano de este trabajo). Para evaluarla, el sistema clásico reduce todo lo que sabe del alumno a un único número: la estimación puntual θ̂, calculada habitualmente por máxima verosimilitud a partir de las respuestas dadas hasta ese momento. Es decir, mientras que el enfoque bayesiano de este artículo mantiene un vector completo de probabilidades sobre las hipótesis de nivel, por ejemplo P = (P(H1), P(H2), P(H3)), el CAT clásico colapsa esa misma información en un único valor θ̂ sobre la recta real (por ejemplo, θ̂ = 0,4) y evalúa la FII de cada pregunta candidata justo en ese punto, no en el resto de valores que θ podría tomar. El criterio bayesiano descrito aquí es preferible cuando el estado del alumno se representa como una distribución completa y no como ese punto único, por dos razones: usa toda la distribución en vez de forzar un colapso a un único valor antes de decidir, si, por ejemplo, la probabilidad está repartida casi por igual entre H1 y H2, θ̂ caerá en un punto intermedio que no representa bien a ningún alumno real, y la FII evaluada justo ahí puede recomendar una pregunta que no sea útil para distinguir entre esas dos hipótesis; y no exige que las hipótesis estén ordenadas en una única escala, lo que permite aplicarlo también a diagnósticos de errores conceptuales sin relación de orden entre sí. Ahora bien, nominal no significa siempre excluyente: si los errores son realmente alternativos, puede usarse una hipótesis por error; pero si varios errores pueden coexistir, el modelo correcto pasa a ser multifactorial o por perfiles completos, y la evidencia ideal no es solo la probabilidad de acierto, sino también qué distractor elige el alumno. El propio protocolo detalla estas variantes cuando las hipótesis no tienen orden.
Cuando varias preguntas tienen una ganancia casi idéntica, algo frecuente cuando comparten dificultad y número de opciones, el sistema no elige siempre la misma: aplica una selección aleatoria ponderada que favorece la variedad de categorías, para evitar que dos sesiones distintas generen la misma secuencia de preguntas.
Criterio de finalización y umbral de entropía
La prueba termina cuando se cumple alguna de estas dos condiciones: se alcanza una convergencia fiable, o se agota el número de preguntas disponibles sin haberla alcanzado. La convergencia fiable exige tres condiciones a la vez, no solo dos: haber respondido un número mínimo de preguntas, que la entropía caiga por debajo de un umbral \(H_{stop}\), y que la hipótesis más probable supere una confianza mínima \(p_{min}\).
El número mínimo de preguntas evita aceptar como firme una estimación basada en muy poca evidencia: antes de alcanzarlo, el sistema sigue preguntando aunque la entropía ya haya cruzado el umbral y una hipótesis ya supere la confianza mínima. De hecho, en el ejemplo numérico de la sección anterior esto ya ocurre tras la primera respuesta: al fallar Q1 la entropía baja a 0,764 bits (por debajo del umbral de 0,92 que se calcula más abajo) y la probabilidad de H1 sube a 0,81 (por encima de 0,80); sin un mínimo de preguntas exigido, el sistema daría ya por bueno un diagnóstico de nivel básico con una sola respuesta. Ese mínimo depende del diseño del recurso: en una etapa breve de práctica puede bastar con 4 preguntas; en un test diagnóstico más amplio puede exigirse un mínimo mayor, por ejemplo 8, junto con una cobertura mínima de dificultades o categorías.
La confianza mínima \(p_{min}\) tampoco es un valor universal: el protocolo puede trabajar con 0,80, 0,85 o cualquier otro valor según el tipo de recurso, la longitud esperada de la prueba, el número de hipótesis y el grado de prudencia deseado. Lo importante es que el umbral de entropía se derive de la confianza mínima elegida y del número de hipótesis consideradas:
Con \(p_{min}=0{,}80\) y n = 3 hipótesis, ese umbral vale aproximadamente 0,92 bits, la línea roja discontinua de la figura 1.
Se exige, además, que entropía y confianza mínima se cumplan juntas y no una sola de ellas, porque no equivalen a lo mismo: una distribución puede tener entropía baja sin que la hipótesis ganadora llegue a esa confianza mínima, si parte de las hipótesis quedan prácticamente descartadas, pero todavía existe una segunda hipótesis con una probabilidad apreciable, en vez de que el resto de la probabilidad se reparta por igual entre todas las demás (de hecho, la condición de confianza implica la de entropía cuando el umbral se deriva de ella; lo que realmente decide el cierre son el mínimo de preguntas y la confianza mínima).
Si el test termina sin cumplir las tres condiciones, el informe final lo indica de forma explícita: el diagnóstico se presenta como provisional, en lugar de ofrecer una falsa seguridad.
Comprobaciones de fiabilidad sin datos empíricos
Como los parámetros del modelo son estimaciones a priori (sección anterior), la metodología incorpora dos comprobaciones que permiten detectar cuándo el resultado no merece confianza, sin necesitar una muestra empírica de alumnado. Es, junto con el criterio de selección por entropía, el segundo punto donde este enfoque se separa de una implementación ingenua de un test adaptativo.
El índice person-fit (\(l_z\)). Detecta si el patrón de respuestas de un alumno concreto es coherente con el nivel que el modelo le ha asignado. Compara la log-verosimilitud observada del patrón de respuestas con la que cabría esperar bajo ese nivel, y estandariza la diferencia:
Bajo el modelo, \(l_z\) se distribuye aproximadamente como una normal estándar. Valores muy negativos (orientativamente \(l_z < -2\)) señalan un patrón improbable bajo el nivel estimado, típicamente acertar preguntas difíciles y fallar las fáciles, o responder al azar, lo que implica que el diagnóstico, aunque el sistema lo presente como «seguro», puede no ser fiable para ese alumno en concreto. La entropía dice cuán segura está la creencia del modelo; el person-fit dice si esa seguridad está justificada por el propio patrón de respuestas.
La validación por simulación (Monte Carlo). Responde a una pregunta distinta: no si un alumno concreto encaja en el modelo, sino si el banco de preguntas en su conjunto distingue bien los niveles. El procedimiento genera alumnos sintéticos situados exactamente en el θ de cada hipótesis, les hace responder de forma simulada (con la misma probabilidad de acierto que marca la curva IRT) y construye una matriz de confusión que compara el nivel real con el nivel diagnosticado. Es una comprobación de la coherencia interna del diseño, calculable antes de aplicar el test a nadie, aunque con un límite importante: los alumnos simulados se generan con el mismo modelo que después los clasifica, así que mide si el diseño discrimina los niveles, no si los parámetros reflejan la realidad de un aula concreta.
Diagnóstico multidimensional por habilidades
En uno de los recursos construidos con esta metodología, un laboratorio de combinatoria, el sistema no se limita a estimar un nivel general por tipo de problema. Mantiene, en paralelo, una distribución bayesiana independiente por cada habilidad transversal implicada (por ejemplo, la lectura del enunciado frente a los pasos de resolución), y todas se actualizan con la misma respuesta del alumno: el resultado global modifica la creencia sobre el nivel, y cada componente de la respuesta modifica la creencia sobre su dimensión correspondiente. Así, la estimación de nivel indica qué tipo de problema conviene practicar, y el diagnóstico por dimensión indica qué paso concreto conviene explicar o reforzar. Este punto no es un adorno técnico: cuando varias dificultades pueden coexistir, separarlas por dimensiones o por perfiles es la forma correcta de no forzar como excluyentes errores que en realidad pueden darse a la vez.
Cuando el ejercicio se corrige por pasos, la respuesta no es únicamente un acierto o fallo: se resume en una puntuación s entre 0 y 1, y la verosimilitud se construye combinando de forma geométrica la de acierto y la de fallo (con exponentes s y 1−s). Así, una respuesta a medias no empuja simplemente hacia el dominio: desplaza la creencia hacia el nivel cuya probabilidad de acierto prevista se parece más a esa puntuación; una puntuación intermedia refuerza un nivel intermedio.
Hipótesis sin relación de orden: la clasificación completa
Todos los ejemplos anteriores comparten un rasgo: sus hipótesis se pueden ordenar. Un nivel básico es menos que un nivel medio, y este menos que uno avanzado, por lo que tiene sentido asignar a cada hipótesis un valor de habilidad θ y usar la función logística de la TRI para generar las verosimilitudes. Pero no todas las preguntas que interesan a un docente son de tipo «cuánto nivel tiene este alumno». A veces la pregunta es «qué le pasa»: si confunde la masa con el peso o la velocidad con la aceleración, si resuelve con la estrategia A o con la B, si su dificultad está en la lectura del enunciado o en el procedimiento. Estas hipótesis son categorías sin relación de orden entre ellas, y la función logística deja de ser el modelo adecuado, porque asume una escala única de «más o menos nivel» que aquí no existe.
La solución no exige cambiar la metodología, sino la fuente de las verosimilitudes. En lugar de calcularlas con una fórmula, se definen directamente para cada pregunta: probabilidad de acierto alta bajo la hipótesis que la pregunta diagnostica bien y probabilidad baja bajo las hipótesis que induce a confusión. Por ejemplo, ante la pregunta «¿la masa de un objeto cambia en la Luna?», un alumno que confunde masa con peso tenderá a fallar (probabilidad de acierto en torno a 0,20), mientras que uno que confunde velocidad con aceleración no se ve afectado por esa pregunta (en torno a 0,80) y uno con dominio correcto acertará casi siempre (0,95). La actualización bayesiana, la entropía y el criterio de parada funcionan exactamente igual; solo cambia de dónde salen las verosimilitudes.
Queda un último caso: cuando varios errores o necesidades pueden darse a la vez. Un alumno puede confundir dos conceptos y, además, leer mal los enunciados. Forzar esas situaciones dentro de una única lista de hipótesis excluyentes sería un error de diseño, porque el sistema se vería obligado a elegir una sola etiqueta para alguien que merece varias. En ese caso se mantiene una distribución separada por cada factor o, si los factores interactúan con fuerza, una única distribución sobre todos los perfiles posibles (todas las combinaciones de presencia y ausencia de cada factor).
La infografía siguiente resume esta clasificación. Cruza dos preguntas de diseño: si las hipótesis se pueden ordenar y si son excluyentes o pueden coexistir. De ahí salen los cuatro casos: ordinal unifactorial (los test de nivel clásicos), ordinal multidimensional (como el laboratorio de combinatoria del apartado anterior), nominal unifactorial (categorías excluyentes con verosimilitudes explícitas) y nominal multifactorial (factores coexistentes, con dimensiones separadas o perfiles completos). Decidir en cuál de los cuatro se está es el primer paso al diseñar un recurso con esta metodología: determina la arquitectura de datos y el modelo matemático antes de escribir la primera pregunta.
Los ejemplos que hay a continuación pueden ayudar a entender los diferentes tipos de hipótesis. Estos programas han sido hechos proporcionándole a la IA el documento llamado Especificación Operativa para IA que está en la web: Recursos educativos adaptativos bayesianos y que tiene las instrucciones necesarias para la implantación completa del método. No es necesario indicarle el tipo de hipótesis que queremos utilizar porque la IA adaptará nuestra petición al que mejor se ajuste.
Ordinal unifactorial (A):
Test adaptativo de cultura general. Se centra en la evaluación y en la asignación del usuario a un grupo de conocimiento (bajo, medio y avanzado).
Ordinal multifactorial (B): Laboratorio de combinatoria. Consta de una fase inicial diagnóstica seguida de otra de refuerzo de los conceptos. Para cada concepto (permutaciones, variaciones y combinaciones, todas con y sin repetición, 12 en total) se proponen ejercicios en aquellos en los que más se falla. También se proporcionan informes sobre habilidades transversales (detección del tipo, conocimiento de la fórmula, repetición o no, etc.).
Nominal unifactorial (C): ¿Frío o caliente? Plantea dos errores mutuamente excluyentes sobre el calor y determina si se tiene alguno de los dos o ninguno.
Nominal multifactorial con factores separados (D): ¿Cómo comparas los decimales? Comprueba varios errores comunes relacionados con los decimales. Son errores no excluyentes, de forma que el programa puede determinar más de uno.
Diagnóstico inicial y refuerzo dirigido en la práctica prolongada
El mismo razonamiento se aplica, por ejemplo, en un itinerario de aprendizaje sobre ecuaciones de primer grado construido con este protocolo, donde decide cuándo dar por superada una etapa y cuándo insertar una tarjeta de refuerzo tras errores repetidos. En estos recursos de práctica prolongada, el diagnóstico no persigue solo un instante final, sino que la selección de preguntas se organiza en dos fases sucesivas, con un objetivo distinto cada una.
Fase diagnóstica inicial. Mientras existan categorías o tipos de problema con muy pocos intentos todavía (por ejemplo, menos de dos), el sistema los prioriza, para evitar sacar conclusiones de una muestra demasiado pequeña. Dentro de esas categorías, elige la pregunta con mayor ganancia esperada de información, igual que en la evaluación descrita en las secciones anteriores.
Fase de refuerzo. Una vez que todas las categorías tienen ya una muestra mínima, el sistema deja de repartir preguntas por igual entre ellas y prioriza la categoría con menor dominio estimado. Además, la pregunta concreta ya no se elige solo por su ganancia de información: se combina con una medida de cercanía a la dificultad del alumno, mediante una puntuación de utilidad del tipo:
con α entre 0,6 y 0,7. Esta separación en dos fases evita un uso excesivo de la entropía: la entropía responde a «dónde tengo más incertidumbre», pero no siempre a «qué necesita practicar más el alumno», y en un recurso de refuerzo interesan ambas preguntas. Para el alumno, esto se traduce en que la práctica no se convierte en una sucesión de ejercicios cada vez más difíciles: una vez detectado en qué tipo de problema falla más, el sistema le da más ejercicios de ese tipo, pero ajustados a una dificultad que todavía puede abordar, en vez de plantarle directamente los más exigentes solo porque son los más informativos para el diagnóstico.
En un recurso de práctica, el alumno aprende mientras practica, y la actualización bayesiana pura da el mismo peso a la primera respuesta que a la última, de modo que la estimación puede quedarse anclada en un estado que el alumno ya ha superado. Para evitarlo, la metodología incorpora un olvido exponencial: en la fase de refuerzo, la creencia acumulada se atenúa ligeramente antes de cada actualización (elevándola a una potencia λ = 0,95 y renormalizando), de modo que la respuesta de hace k ejercicios pesa λᵏ y el sistema recuerda de forma efectiva las últimas ~20 respuestas. Las recientes pesan más que las antiguas y la estimación sigue al alumno cuando mejora. Durante el diagnóstico inicial no se aplica (λ = 1), para no distorsionar el informe inicial. Es la versión mínima de los modelos de transición tipo Bayesian Knowledge Tracing (Corbett y Anderson, 1995), y el laboratorio de combinatoria citado arriba lo implementa.
Diferencias respecto a otros recursos adaptativos
La siguiente tabla resume los puntos en los que esta metodología se aparta de dos referencias habituales: los test adaptativos informatizados (CAT) clásicos de la psicometría, y las plataformas comerciales de aprendizaje adaptativo apoyadas en modelos entrenados con datos masivos de estudiantes.
Aspecto
CAT clásico / plataformas con big data
Esta metodología bayesiana
Estado del alumno
Un valor puntual θ̂ tras cada respuesta.
Una distribución de probabilidad completa sobre varias hipótesis.
Criterio de selección
Función de información del ítem (Fisher), evaluada en θ̂.
Ganancia esperada de información (reducción de entropía) sobre toda la distribución.
Calibración de las preguntas
Requiere datos de una muestra amplia de alumnado real.
Valores a priori razonables, basados en valores de referencia ya publicados en estudios previos de TRI y en la estructura de cada pregunta.
Control de fiabilidad
Suele depender de validaciones estadísticas externas con datos reales.
Person-fit (\(l_z\)) y validación por simulación Monte Carlo, calculables sin datos empíricos.
Alcance del modelo
Pensado sobre todo para evaluación.
Protocolo único aplicable a evaluación, itinerarios, práctica, refuerzo y recomendación.
Autoría
Requiere una plataforma o un equipo de psicometría.
Protocolo documentado y portable, ejecutable por una IA a partir de la especificación del propio docente; los recursos resultantes pueden funcionar enteramente en el navegador del alumno, sin servidores externos.
Resultado final
Puntuación o nivel.
Interpretación pedagógica: dominio, errores probables, recomendación y grado de firmeza del diagnóstico.
La fila de autoría de la tabla anterior requiere una aclaración, porque es la que hace posible el resto de diferencias: el teorema de Bayes, la TRI y la entropía de Shannon no son ideas nuevas, tienen décadas de recorrido en psicometría. Lo que sí es más reciente es formalizarlos como un protocolo escrito, con reglas explícitas, pensado para que una inteligencia artificial genere un recurso completo (banco de preguntas, verosimilitudes, criterio de parada, informe final) a partir de la descripción de un tema, un curso y unos objetivos dados por el docente, sin exigir conocimientos de estadística ni acceso a una base de datos de respuestas de otros alumnos. Eso traslada una técnica hasta ahora reservada a grandes proveedores educativos al alcance de cualquier profesor que quiera construir su propio recurso a medida de un contenido concreto.
Límites de la metodología
Esta metodología no sustituye el criterio docente. Sus resultados deben interpretarse con prudencia cuando hay pocas preguntas disponibles, cuando el banco no está bien calibrado, cuando el alumno responde al azar o cuando la entropía final sigue siendo alta pese a haber terminado la prueba. El propio índice \(l_z\) tiene además una limitación técnica: es una aproximación asintótica, y con pocas preguntas su distribución se aleja de la normal, por lo que el umbral de −2 debe tomarse como una señal de cautela y no como una prueba formal. De la misma manera, la validación por simulación mide la coherencia interna del diseño bajo el propio modelo, no una validez empírica: para eso siguen haciendo falta datos reales de alumnado, algo que esta metodología no pretende sustituir.
Creación de recursos adaptativos con IA, dudas y profundización en la metodología
Los ejemplos citados en este artículo, un test adaptativo de cultura general, un itinerario sobre ecuaciones y un laboratorio de combinatoria, son implementaciones construidas con este protocolo. La implementación utilizando inteligencia artificial (vibe coding) junto con la documentación técnica completa (protocolo y fundamentos matemáticos) está disponible en la web de recursos educativos adaptativos del autor: https://jjdeharo.github.io/recursos-adaptativos/
Birnbaum, A. (1968). Some latent trait models and their use in inferring an examinee’s ability. En Lord, F. M. y Novick, M. R., Statistical Theories of Mental Test Scores. Addison-Wesley. Referencia fundacional del modelo logístico de tres parámetros.
Rasch, G. (1960). Probabilistic Models for Some Intelligence and Attainment Tests. Danmarks Paedagogiske Institut (reeditado por University of Chicago Press, 1980). Modelo de dificultad de ítems.
Cover, T. M. y Thomas, J. A. (2006). Elements of Information Theory (2.ª ed.). Wiley. Entropía de Shannon e información mutua.
Corbett, A. T. y Anderson, J. R. (1995). Knowledge tracing: Modeling the acquisition of procedural knowledge. User Modeling and User-Adapted Interaction, 4(4), 253–278.
van der Linden, W. J. y Hambleton, R. K. (Eds.) (1997). Handbook of Modern Item Response Theory. Springer. Referencia enciclopédica de modelos y aplicaciones de la TRI.
van der Linden, W. J. y Glas, C. A. W. (Eds.) (2010). Elements of Adaptive Testing. Springer. Selección adaptativa de ítems e información.
Drasgow, F., Levine, M. V. y Williams, E. A. (1985). Appropriateness measurement with polychotomous item response models and standardized indices. British Journal of Mathematical and Statistical Psychology, 38(1), 67-86. Índice estandarizado de ajuste de la persona ($l_z$).
López Pina, J. A. (2026). Teoría de la Respuesta al Ítem: Fundamentos y modelos. Editum, Ediciones de la Universidad de Murcia. DOI: 10.6018/editum.3178. En español y de acceso abierto.
Wainer, H. (Ed.) (2000). Computerized Adaptive Testing: A Primer (2.ª ed.). Lawrence Erlbaum. Fundamentos de la evaluación adaptativa.
Gelman, A. et al. (2013). Bayesian Data Analysis (3.ª ed.). CRC Press. Inferencia bayesiana general.
OpenWorksheets (OWS) es una aplicación web libre para crear fichas interactivas y autocorregibles a partir de un PDF, una imagen o una hoja en blanco.
Pantalla inicial de OpenWorksheets
El profesorado prepara su ficha, coloca encima los campos de respuesta y define las soluciones. Después, el alumnado la resuelve desde el navegador y el docente puede revisar las entregas, ver la puntuación y exportar los resultados.
OWS tiene como bandera la libertad, privacidad, portabilidad y reutilización sin depender de una plataforma cerrada. No necesita cuentas de usuario ni servidores externos, ya que todo funciona en el navegador del profesorado y en el del alumnado. La comunicación entre ambos se realiza mediante archivos de entrega cifrados, que tienen extensión .owsub (OpenWorksheets submissions) o a través de una URL (también cifrada) que se envía directamente al docente.
Pantalla inicial del editor con las diferentes formas de crear una ficha.
Las formas que tenemos para crear una ficha (proyecto) son:
Añadir PDF o imagen, esta es la forma habitual. Podemos abrir un PDF o una imagen para dibujar encima los campos autocorregibles de forma que podemos aprovechar documentos ya existentes.
Abrir una ficha ya creada con extensión .owpkg (OpenWorksheets package). Podremos continuar trabajando en un proyecto guardado anteriormente.
Comenzar con una hoja en blanco sobre la cual podremos crear nuestra ficha.
Crear con IA permite producir una ficha a partir de una página en blanco con los parámetros que definamos (nivel, tema, tipos de campos deseados, etc.). Se utilizan los tipos de campo que pueden generarse automáticamente; quedan fuera los que dependen directamente de recortes o zonas del PDF. OWS generará un prompt que podremos pegar en nuestra IA de cabecera.
Un proyecto abierto (ficha). En la parte izquierda accedemos a los botones para crear campos, las miniaturas y a la derecha la lista de todos los campos y sus propiedades cuando se selecciona uno.
Además, las fichas pueden guardarse como archivo propio (.owpkg), exportarse como página web autónoma y compartirse mediante enlace (previa subida a la nube obteniendo un enlace público), como web incrustada en otra o integrarse en Moodle y otros LMS mediante SCORM 1.2.
La aplicación admite muchos tipos de respuesta: texto corto, respuesta numérica, fórmulas matemáticas o químicas, verdadero/falso, opción única o múltiple, desplegables, huecos, tablas editables, emparejamientos, ordenar elementos, arrastrar a zonas, unir con flechas, respuesta larga y grabación de voz. También permite insertar imágenes, audio, vídeo, contenido HTML, paquetes de eXeLearning, IMS CP y SCORM.
Como profesor de matemáticas y ciencias, soy especialmente sensible a la posibilidad de crear fórmulas. Cualquier texto de la ficha puede incluir fórmulas LaTeX. Además, el editor de fórmulas de elaboración propia, EdiCuaTeX, se integra de forma natural para permitir la edición visual sin conocimientos de LaTeX, tanto en la parte del profesorado como en la del alumnado. No obstante, soy consciente de que una gran parte del profesorado no usará nunca fórmulas en sus fichas, por ese motivo se pueden desactivar en la configuración de la ficha.
OpenWorksheets también incorpora opciones de seguridad y privacidad: cifrado de la ficha, cifrado de entregas, verificación de integridad, restricciones de acceso, tiempo límite y supervisión ligera durante la realización. Un semáforo de seguridad indica su nivel en la barra superior.
Flujo de trabajo
El flujo de trabajo más habitual es compartir la ficha mediante un enlace o código QR:
El profesor crea la actividad en el editor a partir de un PDF, una imagen, IA o una hoja en blanco.
Añade los campos de respuesta y configura las soluciones, la puntuación y las opciones de corrección.
Exporta la ficha como paquete .owpkg.
Sube ese paquete a Google Drive o a otro alojamiento público.
En Google Drive, activa la opción Cualquier persona con el enlace y copia la URL pública del archivo.
Pega esa URL en OpenWorksheets para generar el enlace final del alumnado.
Comparte ese enlace con los estudiantes.
El alumnado abre la ficha en el navegador, la completa y entrega sus respuestas mediante archivo o enlace de entrega.
El docente abre las entregas en OpenWorksheets, comprueba su integridad, revisa las respuestas, ajusta las correcciones manuales si las hay y exporta los resultados a CSV.
Además de este flujo principal, OpenWorksheets permite otras formas de uso:
Exportar la ficha como página web autónoma, para publicarla a través de una página web.
Integrarla en Moodle u otro LMS mediante SCORM 1.2.
Exportarla como IMS Content Package.
Embeberla en otra página mediante un iframe.
Cuadro de diálogo para compartir una ficha. Antes se tiene que subir la ficha a un servicio público de almacenamiento como Google Drive.
Una ficha tal como la ve el alumnado. En la esquina inferior derecha tiene la opción de finalizarla.
OpenWorksheets permite crear, compartir y corregir fichas interactivas con un enfoque abierto, portable y respetuoso con la privacidad. La intención es que el profesorado pueda conservar el control sobre sus materiales y utilizarlos en distintos contextos, sin depender de una plataforma cerrada.
Puedes ver una descripción de las posibilidades más completa en la página de las características del programa.
Nota: Este artículo tiene nivel 4 en el marco MIAE.
Cuando una tarea puede ser resuelta íntegramente por IA, el producto final deja de ser una evidencia suficiente de aprendizaje. La respuesta no debería ser prohibir la IA ni confiar en detectores poco fiables, sino rediseñar las actividades para que el proceso deje huellas observables.
La estrategia no debe basarse en buscar actividades que no puedan ser imitadas por la IA o que requieran un nivel de abstracción que esta no pueda alcanzar. En muchas tareas escolares, especialmente cuando están bien formuladas y se proporciona suficiente información, la IA puede producir respuestas de una calidad igual o superior a la esperada en buena parte del alumnado.
El objetivo de este artículo es proponer criterios para diseñar actividades en las que la IA pueda utilizarse como herramienta sin sustituir el aprendizaje del alumnado. La diferencia está entre utilizarla como apoyo o delegar en ella la tarea. En el primer caso, el alumno mantiene el control del proceso: pregunta, contrasta, selecciona, revisa, corrige y justifica sus decisiones. En el segundo, entrega un producto que no ha elaborado realmente, no comprende suficientemente o no puede defender. El problema no es simplemente que se use IA, sino que el alumno desaparezca del proceso. Esta distinción, entre apoyo y delegación, es el criterio que recorre todas las características que se proponen a continuación.
Este artículo no pretende ofrecer un modelo cerrado ni una solución definitiva al problema de la evaluación en presencia de IA. Se trata de una propuesta de trabajo para orientar el diseño de actividades y evidencias de aprendizaje en un contexto en el que los productos escritos aislados han perdido parte de su valor como prueba de autoría y comprensión.
Las ideas que se presentan deberán adaptarse a cada materia, etapa educativa, grupo de alumnos y finalidad de la evaluación. En algunos casos bastará con una evidencia sencilla, como una pregunta oral o una observación breve durante la actividad. En otros, especialmente cuando la tarea tenga mayor peso evaluativo o permita un uso amplio de la IA, será necesario combinar varias evidencias para obtener una imagen más fiable del aprendizaje.
La IA como herramienta
La presencia creciente de la IA y su grado de penetración en la vida cotidiana hacen inviable su prohibición. Algo que además no es deseable porque forma parte del mundo en el que vivimos y la escuela debe preparar al alumnado para ese mundo, no aislarlo de él.
Debemos incorporar la IA como una herramienta más, clarificando previamente, antes de cada trabajo, el uso que se puede hacer de ella. Para ello puede ser útil una escala para la utilización de la IA, como el marco MIAE, con el que se puede graduar su uso desde su ausencia total, pasando por diversos grados de utilización con diferentes funciones. La siguiente imagen muestra de forma esquemática este marco.
Aunque existen otros marcos útiles, como AIAS, centrado especialmente en la integridad académica y la evaluación, o SEIA, que incorpora también dimensiones como la supervisión, la equidad y el DUA, se utilizará MIAE porque permite clasificar de forma más directa el papel que desempeña la IA en cada tarea: reformular, planificar, generar un borrador, colaborar en el proceso o producir un resultado que después debe ser supervisado por la persona.
En cualquier tarea susceptible de ser hecha con IA, el profesorado debería determinar el nivel que permitirá. Un ejercicio de ortografía o de cálculo puede necesitar nivel 0 (ausencia total de IA). Una redacción sobre un tema determinado puede beneficiarse de una corrección de estilo (nivel 1). La preparación de un trabajo de investigación puede utilizar la IA para hacer una lluvia de ideas (nivel 2). Los niveles superiores no deben descartarse, pero requieren un diseño más cuidadoso, porque el centro de la actividad ya no está en producir una respuesta, sino en dirigir, revisar, justificar y mejorar el trabajo realizado con apoyo de la IA.
Características de las evidencias
Una vez definido el nivel de IA permitido, la evaluación debe comprobar no solo el producto final, sino también si el alumnado ha trabajado dentro de ese nivel y qué aprendizaje puede demostrar a partir del proceso seguido. Para ello proponemos una serie de características que deben cumplir las evidencias generadas por el alumnado.
Conviene tener en cuenta que estas características no operan en el mismo plano, ya que algunas describen cómo se diseña la evaluación (trazabilidad, contextualización, triangulación), otras el soporte en que se manifiesta la evidencia (oralidad, presencialidad, materialidad) y otra es una condición que debe cumplir el alumnado (transparencia en el uso de IA). El cruce entre ellas es lo que aporta fiabilidad.
Trazabilidad del proceso. Trabajo en el aula, borradores revisados durante la actividad, registros del docente, rúbricas de proceso, cuadernos de clase o de campo y otras evidencias del proceso. No se valora solo el resultado final, sino cómo el alumno trabaja, decide, se equivoca, corrige y avanza. La trazabilidad no garantiza por sí sola la autoría, ya que también puede simularse con IA, pero permite contrastar mejor el proceso y evita que la evaluación dependa únicamente de un producto final aislado. Por eso las evidencias de proceso resultan más fiables cuando se cruzan con evidencias de presencialidad u oralidad.
Contextualización. La evidencia se vincula a experiencias, datos, observaciones, discusiones o decisiones producidas en el aula. Cuanto más dependa de lo que ha ocurrido realmente en el grupo, menos sustituible será por una respuesta genérica generada por IA.
Oralidad. Intercambios orales, entrevistas evaluativas, defensas, preguntas estructuradas, debates y otras situaciones de comunicación oral. El alumno debe explicar, argumentar, reformular y responder en el momento, especialmente cuando se le pide relacionar la respuesta con aquello que se ha hecho o discutido en el aula.
Presencialidad. Observación sistemática, prácticas de laboratorio, talleres, pruebas prácticas, dramatizaciones, debates, coloquios, entre otros. La IA no puede “estar” en el aula ni sustituir aquello que el alumno hace en tiempo real ante el docente.
Materialidad. Maquetas, prototipos, preparaciones, modelos físicos, murales, pruebas prácticas y otras producciones materiales o actuaciones observables. Producen objetos reales o actuaciones que implican habilidades manuales, toma de decisiones y presencia del alumno.
Triangulación. Combinación de observaciones, producciones, pruebas prácticas, interacciones orales, registros de proceso, autoevaluaciones, coevaluaciones y otras fuentes de información. La decisión evaluativa no depende de una única evidencia, sino del contraste entre varias fuentes.
Transparencia en el uso de IA. Cuando la actividad permite utilizar inteligencia artificial, el alumnado debe indicar cómo la ha usado: para generar ideas, corregir, resumir, buscar alternativas, revisar errores o mejorar la presentación. Esta declaración no debe limitarse a copiar los prompts, sino explicar qué aportó la IA, qué decisiones tomó el alumno y qué partes aceptó, modificó o descartó. Esta transparencia es imprescindible cuando se permite el uso de IA, aunque sea mínimo, para que el alumnado se acostumbre a declarar qué uso ha hecho de la herramienta y qué responsabilidad mantiene sobre el resultado.
No todas las actividades necesitan el mismo grado de control ni la misma cantidad de evidencias. En una tarea breve puede bastar con indicar el nivel de IA permitido y pedir una justificación mínima del uso realizado. En una actividad de mayor peso, como un trabajo de investigación, una presentación o un proyecto, sí puede ser necesario recoger alguna evidencia del proceso: un esquema inicial, una versión intermedia, una explicación oral breve o una reflexión final.
La finalidad no es multiplicar la carga de corrección del profesorado, sino evitar que toda la evaluación dependa de un producto final que puede haber sido generado por IA. Por eso, conviene que sean coherentes con la tarea y limitadas a lo necesario, basta con una muestra del proceso o una justificación de las decisiones tomadas.
Ejemplos según el nivel de uso de la IA
Nivel 0. Sin IA. Prueba breve en el aula. La evidencia es la propia realización presencial.
Nivel 1. IA para revisión formal. Redacción escrita por el alumno y revisada con IA. Se entrega la versión final y se señalan dos o tres cambios realizados con ayuda de la IA.
Nivel 2. IA para planificar. En la creación de una maqueta, la IA puede usarse para obtener ideas sobre materiales, estructura o forma de representar el contenido. La maqueta debe ser construida por el alumnado y acompañarse de una explicación breve sobre qué idea se aprovechó, qué se cambió y por qué.
Nivel 3. IA como borrador inicial. En una presentación sobre un tema trabajado en clase, la IA puede generar una primera estructura o un borrador de guion. El alumnado entrega el resultado final y marca qué partes ha cambiado, ampliado o corregido.
Nivel 4. Cocreación con IA. En un proyecto breve, el alumnado utiliza la IA durante el proceso para pedir propuestas, revisarlas, hacer cambios y mejorar el resultado. No se corrige toda la conversación: se pide una selección de tres decisiones importantes tomadas durante el trabajo.
Nivel 5. IA autónoma supervisada. La IA produce un texto explicativo completo. El alumnado lo somete a una auditoría crítica y defiende oralmente sus conclusiones: qué errores detectó, qué decidió y por qué. La evidencia de aprendizaje es esa defensa, no la simple aceptación o rechazo del producto.
Para facilitar la selección de evidencias adecuadas a cada característica, puede recurrirse a un catálogo de recursos ya organizado con ese fin.
METACEVAL: Recursos metodológicos para el aula
METACEVAL es un catálogo en línea que contiene más de 180 técnicas y metodologías activas, así como más de 185 recursos de evaluación, entre los que se encuentran más de 85 evidencias de evaluación. Hemos seleccionado algunas evidencias que encajan bien en cada una de las características de las evidencias. Una misma evidencia puede aparecer en varias características, ya que un mismo recurso puede servir a propósitos distintos según cómo se utilice.
Revisar una versión intermedia en clase, observar cómo el alumno empieza, se bloquea, corrige o mejora, comparar el plan inicial con lo que realmente se hizo, registrar decisiones tomadas durante una práctica, proyecto o trabajo cooperativo.
Usar datos obtenidos en una práctica, pedir que se relacione el producto con una discusión de clase, resolver una variante basada en un caso trabajado en el aula, interpretar una gráfica, fuente o situación vinculada al contexto de la actividad.
Pedir al alumno que explique una decisión, justifique un cambio, reformule una idea, responda a una pregunta imprevista o defienda cómo ha usado la IA en una parte concreta del trabajo.
Realizar una parte de la tarea en clase, aplicar una lista de comprobación durante la sesión, resolver una pregunta breve sin ayuda externa, observar la ejecución de un procedimiento en tiempo real.
Valorar un montaje, preparación, modelo físico, prototipo, actuación, experimento, póster defendido oralmente o producto manipulativo que obligue a aplicar procedimientos y tomar decisiones observables.
Combinar producto final, observación del proceso y defensa oral, contrastar una práctica con una explicación breve, cruzar porfolio, notas de campo y entrevista, no basar la evaluación en una única entrega escrita.
Pedir que el alumno explique qué pidió a la IA, qué aceptó, qué modificó y qué descartó, seleccionar una o dos decisiones relevantes, contrastar el uso declarado con una versión intermedia, una pregunta oral o una revisión presencial.
Conclusión
La clave no está en impedir cualquier uso de IA, sino en definir con claridad qué uso se permite y qué evidencias deberá aportar el alumnado. Sin esas evidencias, el producto final puede ser correcto, estar bien redactado y cumplir la consigna, pero no demostrar necesariamente aprendizaje. Por eso, las evidencias deben ser pocas, significativas y coherentes con la tarea: una decisión justificada, una corrección razonada, una explicación oral, una versión intermedia o una muestra del proceso seguido. Así, la evaluación deja de apoyarse solo en lo que se entrega y pasa a centrarse en lo que el alumno puede demostrar que ha comprendido, decidido y aprendido.
Podcast creado con NotebookLM
Nota: Este artículo tiene nivel 3 en el marco MIAE.
Los recursos educativos adaptativos permiten que una actividad cambie según las respuestas del alumno. En este artículo veremos dos ejemplos y un protocolo para crear este tipo de recursos con IA. Para el que lo desee hay también un anexo matemático con la metodología utilizada.
Introducción a los recursos adaptativos
Los recursos educativos suelen ser lineales, por ejemplo, un test de evaluación es el mismo para todos. De la relación entre aciertos y errores obtendremos una calificación y, con suerte, un análisis de lo que cada alumno ha fallado y lo que le conviene mejorar.
Si esa misma evaluación la hacemos adaptativa, el sistema se acomoda a las respuestas del alumno, aprende de sus fallos y aciertos y ambos se convierten en información: El sistema debe usar las respuestas del alumno como evidencias para actualizar hipótesis sobre su estado de aprendizaje. Estas hipótesis pueden ser niveles de aprendizaje, de dificultad, errores conceptuales, etc. El sistema adaptativo no hace las mismas preguntas a todos, sino que las adapta según las respuestas realizadas hasta el momento por el alumnado.
El sistema adaptativo aprende de las respuestas del alumno para proponerle preguntas adaptadas a su nivel, de refuerzo si detecta errores o de ampliación y continuación más avanzada si detecta que puede hacerlo.
Esto puede hacerse con cualquier recurso, no estamos limitados a la evaluación. Por ejemplo, con un itinerario de aprendizaje, un juego educativo, un tutorial interactivo y cualquier recurso educativo digital en el que tenga sentido la adaptación a las diferentes tipologías y necesidades del alumnado.
Ejemplo 1: Test adaptativo para la evaluación diagnóstica
Hemos hecho dos ejemplos. El primero es un test de evaluación de cultura general. Fue el primero, hecho a modo de demo educativa, y permite evaluar nuestros conocimientos en tres niveles: básico, medio y avanzado. Cada vez que respondemos una pregunta, el sistema nos hace otra, de forma que la información que recibe de la respuesta es máxima para conocer nuestro nivel. De esta forma va adaptando las preguntas hasta que tiene información suficiente para decidir el nivel que tenemos en este tema. Para que esto sea significativo, las preguntas deben estar correctamente clasificadas en los 3 niveles. Las preguntas han sido generadas mediante IA, pero podríamos habérselas suministrado ya clasificadas cada una en su nivel.
El programa no solo determina el nivel del usuario, proporcionando el porcentaje de la probabilidad de pertenencia a cada uno, sino que crea un informe con aquellos aspectos en los que se puede mejorar y los que ya se dominan. Estos aspectos son los diferentes temas motivo de las preguntas (ciencias, historia, etc.).
Es importante remarcar que 7/10 no debe entenderse como una nota, ya que las preguntas han sido hechas para diagnosticar el nivel de conocimientos y lo que realmente importa es el nivel alcanzado. De ahí que sea una evaluación diagnóstica, pero no calificadora. Podríamos tener notas superiores o inferiores, de forma un tanto aleatoria, según los niveles en los que hubiésemos respondido. Es decir, un alumno que solo es capaz de responder cuestiones de nivel básico podría sacar un 8/10 y otro capaz de responder preguntas con más dificultad un valor inferior, precisamente porque, al ser capaz de responder preguntas más complejas, se le han hecho más de este tipo. Estas preguntas han servido para hacer un diagnóstico, pero no determinan una nota. No se hace un número fijo de preguntas; cuando el sistema tiene la certeza de que el alumno pertenece a una categoría determinada, entonces para de hacerlas. En el anexo se explica con más detalle el método utilizado.
Ejemplo 2: Itinerario adaptativo
El siguiente ejemplo es una aplicación, llamada Despejar la incógnita x, que permite practicar la técnica para despejar incógnitas en una ecuación de primer grado. El itinerario consta de tres etapas.
En primer lugar, muestra la técnica que se usará en cada etapa. Se le pueden pedir tantos ejemplos resueltos como se quiera.
Cuando se decide practicar la etapa, el sistema examina las respuestas para determinar si se domina o no la técnica correspondiente. En este programa se ha limitado a un mínimo de 4 respuestas para el que las resuelva correctamente y un máximo de 10 para el que no.
En el caso de no superar una etapa, el programa dará la oportunidad de repetirla de nuevo o continuar con el resto del itinerario.
Una vez terminadas las 3 etapas, el sistema da una indicación del progreso (iniciando, avanzando o dominando) y un informe de los puntos fuertes y débiles.
Debemos destacar que el número de ejercicios propuestos, las ayudas recibidas y el avance por las etapas vienen determinados por las respuestas del alumno. El itinerario mantiene una estructura progresiva, pero se adapta dentro de cada etapa y decide cuándo conviene avanzar, reforzar o repetir.
Cómo crear aplicaciones educativas con vibe coding
Hemos preparado la web Recursos educativos adaptativos bayesianos desde donde podrás descargar el archivo llamado Protocolo de recursos adaptativos bayesianos, con instrucciones para la inteligencia artificial. Este archivo deberás proporcionárselo a la IA para que sepa qué debe hacer. Este mismo documento lo puedes consultar en formato web en la página anterior.
Casi con toda seguridad, la inteligencia artificial no hará bien el programa a la primera, por lo que deberás comprobar si lo que ha hecho se adapta a tus necesidades y, a través del diálogo con la IA, adaptar el recurso hasta que esté realmente preparado.
Pódcast del artículo realizado por NotebookLM
Anexo: Metodología matemática utilizada
Esta parte solo es para los interesados en conocer los entresijos matemáticos que forma la metodología adaptativa utilizada por el protocolo anterior.
Inferencia bayesiana
El teorema de Bayes permite actualizar la probabilidad de una hipótesis cuando obtenemos una nueva evidencia. Es decir, partimos de una idea inicial sobre el nivel (o la categoría que hayamos definido) del alumno y la vamos modificando a medida que responde preguntas.
En un recurso adaptativo, las hipótesis pueden ser, por ejemplo: el alumno tiene un nivel básico, medio o avanzado.
Al comenzar, el sistema todavía no sabe cuál de estas hipótesis es la más probable, así que se asigna la misma probabilidad a todos:
\(P(\text{básico}) = 33.3%\)
\(P(\text{medio}) = 33.3%\)
\(P(\text{avanzado}) = 33.3%\)
Estas probabilidades iniciales se llaman probabilidades previas. Representan lo que el sistema cree antes de observar la respuesta del alumno.
Cuando el alumno contesta una pregunta, aparece una nueva evidencia, ya que ha acertado o ha fallado una pregunta de cierto nivel. Esa respuesta modifica las probabilidades anteriores. Si acierta una pregunta avanzada, aumentará la probabilidad de que pertenezca al nivel avanzado. Si falla varias preguntas básicas, aumentará la probabilidad de que necesite refuerzo en ese nivel.
En forma matemática, el teorema de Bayes se expresa así:
Donde \(P(H \mid E)\) es la probabilidad de la hipótesis después de observar la evidencia. En nuestro caso, sería la probabilidad de que el alumno tenga un determinado nivel después de ver su respuesta.
\(P(H)\) es la probabilidad previa de esa hipótesis, antes de la respuesta.
\(P(E \mid H)\) es la probabilidad, llamada verosimilitud, de observar una determinada respuesta del alumno si una hipótesis concreta fuera cierta. Por ejemplo, qué probabilidad habría de que un alumno de nivel avanzado acertara una pregunta avanzada.
\(P(E)\) es la probabilidad de observar esa evidencia, sin saber todavía cuál es el nivel real del alumno. En nuestro ejemplo, sería la probabilidad global de que el alumno acierte una pregunta avanzada, antes de decidir si pertenece al nivel básico, medio o avanzado.
Aplicado a un test adaptativo, el razonamiento sería el siguiente:
Si un alumno fuera de nivel avanzado, sería bastante probable que acertara esta pregunta difícil. Si fuera de nivel básico, sería poco probable que la acertara. Como la ha acertado, aumenta la probabilidad de que sea de nivel avanzado.
Y al contrario:
Si un alumno falla una pregunta básica, esa respuesta es más compatible con la hipótesis de que necesita refuerzo. Por tanto, el sistema aumenta la probabilidad de que esté en un nivel inicial o de que tenga dificultades en ese contenido.
Lo importante es que el sistema no toma una única respuesta como definitiva. Cada respuesta modifica un poco el diagnóstico. Después de varias preguntas, las probabilidades se van separando: una hipótesis gana peso y otras lo pierden.
Por ejemplo, después de varias respuestas, el sistema podría obtener algo así de un alumno en particular:
\(P(\text{básico}) = 12%\)
\(P(\text{medio}) = 31%\)
\(P(\text{avanzado}) = 57%\)
Esto no significa que el alumno tenga una nota de 5,7 ni que haya acertado el 57 % de las preguntas. Significa que, según las respuestas observadas, el sistema considera que la hipótesis más probable es que el alumno se encuentre en el nivel avanzado.
Esta es la diferencia principal respecto a un test tradicional. En un test lineal, las respuestas se acumulan para obtener una puntuación. En un test adaptativo bayesiano, las respuestas se utilizan como evidencias para actualizar un diagnóstico.
El mismo principio puede aplicarse a otros tipos de recursos. En un itinerario de aprendizaje, la hipótesis no tiene por qué ser “nivel básico, medio o avanzado”, sino que puede ser “domina la técnica”, “está en proceso” o “necesita refuerzo”. Cada ejercicio resuelto aporta una nueva evidencia y permite decidir si conviene avanzar, repetir, ofrecer una explicación adicional o proponer actividades de mayor dificultad.
La inferencia bayesiana permite que el recurso educativo no siga un camino fijo, sino que tome decisiones a partir de la información que va obteniendo del alumno.
Verosimilitudes y modelo IRT 3PL
Para que Bayes actualice las probabilidades, el sistema calcula las verosimilitudes. En las preguntas o actividades organizadas por niveles de dificultad, estas verosimilitudes se generan mediante el modelo IRT 3PL (Item Response Theory, three-parameter logistic model), es decir, el modelo logístico de tres parámetros de la teoría de respuesta al ítem.
La idea general es que la probabilidad de acertar una pregunta aumenta cuando el nivel hipotético del alumno supera la dificultad de la pregunta, y disminuye cuando la dificultad supera el nivel hipotético del alumno.
Donde \(\theta_i\) representa numéricamente la hipótesis o nivel \(H_i\), \(b_q\) representa la dificultad de la pregunta o actividad, \(a\) es el parámetro de discriminación y \(c_q\) es la probabilidad mínima de acierto por azar.
En el modelo IRT 3PL, estos tres parámetros tienen una función concreta: \(b_q\) sitúa la dificultad del ítem, \(a\) indica cuánto discrimina entre niveles próximos y \(c_q\) establece el suelo de probabilidad de acierto.
En preguntas de opción múltiple, este suelo se calcula a partir del número de opciones:
\[ c_q=\frac{1}{m_q} \]
Por ejemplo, en una pregunta de cuatro opciones:
\[ c_q=\frac{1}{4}=0{,}25 \]
Esto significa que la probabilidad de acierto no se considera inferior al 25 %, porque incluso un alumno que responde al azar tiene esa probabilidad de acertar.
Si el alumno falla, se usa la probabilidad complementaria:
Estas probabilidades de acierto y fallo son las verosimilitudes que utiliza Bayes para actualizar el diagnóstico.
El modelo IRT 3PL no sustituye al teorema de Bayes. Su función es generar las verosimilitudes que Bayes necesita para hacer la actualización.
En recursos que no son tests, la misma lógica se aplica a preguntas, pasos, retos o actividades autocorregibles, siempre que se representen mediante una dificultad, una respuesta observable y una interpretación del resultado. La evidencia es un acierto, un fallo, un paso superado, una pista solicitada, un intento adicional o un error detectado, siempre que el recurso haya definido cómo se traduce esa actuación en una evidencia utilizable.
Cuando las hipótesis no son niveles ordenados, por ejemplo, distintos errores conceptuales, el modelo IRT 3PL no es el adecuado, porque presupone una escala común de nivel o dominio. En esos casos, las verosimilitudes se definen según la relación diagnóstica entre cada actividad y cada hipótesis. La actualización bayesiana sigue siendo la misma; lo que cambia es la forma de obtener las verosimilitudes.
Entropía de Shannon
La incertidumbre del sistema se mide mediante la entropía de Shannon:
\[ H=-\sum_i p_i\log_2(p_i) \]
Donde \(p_i\) es la probabilidad actual de cada hipótesis.
Cuando las probabilidades están muy repartidas, la entropía es alta. Por ejemplo, si básico, medio y avanzado tienen probabilidades parecidas, el sistema todavía no tiene un diagnóstico claro.
Cuando una hipótesis concentra la mayor parte de la probabilidad, la entropía baja. En ese caso, el sistema tiene más seguridad sobre el estado del alumno.
La entropía se usa para tres cosas: medir la incertidumbre del diagnóstico, seleccionar actividades que aporten información y decidir si el proceso finaliza.
Selección adaptativa y ganancia de información
Después de actualizar las probabilidades, el sistema decide qué pregunta, explicación, pista, ejercicio o actividad presenta a continuación.
Esta selección no se basa simplemente en subir la dificultad tras un acierto y bajarla tras un fallo. El método utilizado es la ganancia esperada de información. Es decir, el sistema estima qué actividad reduce más la incertidumbre sobre el estado del alumno.
Como la incertidumbre se mide con la entropía de Shannon, la ganancia de información se calcula como una reducción esperada de entropía. De forma simplificada:
Para cada posible actividad, el sistema calcula qué ocurre si el alumno la supera y qué ocurre si no la supera. En cada caso estima cómo cambian las probabilidades de las hipótesis y qué entropía tiene la nueva distribución. Después compara la entropía actual con la entropía esperada tras esa actividad.
La actividad más adecuada es la que distingue mejor entre las hipótesis que todavía son plausibles. Por eso, la mejor pregunta no siempre es la que coincide exactamente con el nivel más probable. Si el sistema duda entre nivel medio y avanzado, una pregunta difícil resulta más informativa que una pregunta media. Si duda entre nivel básico y medio, selecciona una pregunta más sencilla o intermedia.
Cuando varias actividades tienen una ganancia de información muy parecida, el sistema introduce diversidad de contenidos. Así evita repetir siempre el mismo tipo de pregunta o el mismo concepto cuando hay varias opciones igualmente útiles.
Criterio de parada y resultado final
El proceso se detiene cuando el sistema alcanza una confianza suficiente, cuando la entropía baja por debajo de un umbral previsto, cuando se llega al número máximo de preguntas o pasos, o cuando las actividades disponibles ya no aportan información relevante.
El resultado final no se limita a una etiqueta ni a una puntuación. Se presenta como una interpretación pedagógica: qué parece dominar el alumno, qué dificultades muestra, qué conviene reforzar y con qué grado de seguridad se propone el diagnóstico.
Si la incertidumbre sigue siendo alta, el sistema lo indica claramente. En ese caso, el resultado se presenta como una estimación provisional basada en las evidencias disponibles, no como una conclusión definitiva.
Esta es la diferencia principal respecto a un recurso educativo lineal. En una secuencia fija, todos los alumnos recorren el mismo camino y sus respuestas solo sirven para avanzar, retroceder o recibir una puntuación. En un recurso adaptativo bayesiano, cada respuesta o actuación se utiliza como evidencia para actualizar un modelo del estado del alumno y decidir cuál debe ser el siguiente paso: una nueva pregunta, una explicación, una pista, una actividad de refuerzo, una propuesta de ampliación, un cambio de itinerario o una recomendación de recursos.
Un repertorio abierto para encontrar, relacionar y aplicar recursos didácticos en la práctica docente.
¿Por qué nace METAC?
METAC tiene su origen en 2022, antes de la aparición pública de la IA generativa, como un intento de ordenar y sistematizar las numerosas metodologías activas existentes. Muchas de ellas suelen presentarse de forma aislada, con descripciones incompletas o sin una relación clara con otros recursos de aula.
El proyecto inicial se llamó METEC, aunque el acrónimo previsto era METAC, formado a partir de METodologías ACtivas. METEC surgió por una errata tipográfica y finalmente conservó ese nombre. Todavía puede consultarse en https://metec.tiddlyhost.com.
Con el desarrollo actual de la inteligencia artificial, ha sido posible ampliarlo, añadir nuevos ejemplos, mejorar los ya existentes y traducir el contenido a varios idiomas, siempre con revisión y criterio pedagógico.
Mi formación como zoólogo, y mi tendencia taxonómica a ordenar, comparar y jerarquizar, me han llevado a ampliar y reorganizar el proyecto inicial. De ahí surge METAC.
El nombre, sin embargo, ha quedado corto. METAC ya no incluye solo metodologías activas, sino también técnicas, rutinas, estrategias, marcos educativos, recursos de evaluación, propuestas metacognitivas y programas de apoyo. Por eso, más que un catálogo de metodologías activas, METAC es un compendio de recursos metodológicos para el aula.
Qué es METAC
Como acabamos de decir, es un repertorio web de recursos metodológicos para el aula, pensado para ayudar al profesorado a localizar, comprender, relacionar y aplicar propuestas didácticas de forma rápida y ordenada.
La información se agrupa en tres grandes bloques:
Marcos educativos: enfoques generales que orientan la práctica docente y ayudan a diseñar propuestas coherentes de enseñanza y aprendizaje. Por ejemplo, DUA, Modelo SAMR o Diseño inverso.
Organización del aprendizaje cooperativo: recursos para estructurar el trabajo en equipo, favorecer la participación y mejorar la cooperación entre el alumnado. Por ejemplo, 1-2-4, Lápices al centro o Folio giratorio.
Metodologías activas: técnicas, rutinas, estrategias y métodos que implican al alumnado en procesos de análisis, creación, resolución de problemas, reflexión y toma de decisiones. Por ejemplo, Aprendizaje basado en proyectos, Aprendizaje basado en problemas o Clase invertida.
Además de estos tres bloques, METAC utiliza una segunda forma de organización: los ámbitos. Mientras que los bloques indican el tipo general de recurso, los ámbitos indican para qué puede ser útil en el aula.
Un mismo recurso puede pertenecer a más de un ámbito, porque muchas técnicas no sirven para una sola cosa. Por ejemplo, una rutina puede favorecer el pensamiento crítico y, al mismo tiempo, mejorar la comunicación; una dinámica cooperativa puede servir para organizar el trabajo en equipo, pero también para activar ideas previas o facilitar la evaluación formativa.
Podemos usar los selectores de la parte superior de forma conjunta o independiente, también podemos utilizar el buscador para encontrar cualquier texto que esté en los recursos.
Fichas de recursos
En cada ficha mostrada en METAC se indica el bloque, el ámbito y un resumen del recurso. Además, si hay un recurso asociado, normalmente un programa, aparecerá el icono de una cadena. Una estrella nos permite añadirlo o eliminarlo de favoritos.
Al pulsar sobre la ficha obtendremos el recurso completo.
En la parte superior disponemos de una serie de botones:
Añadir a favoritos.
Copiar el recurso para pegar en algún programa.
Imprimir en PDF.
Copiar el enlace a ese recurso en particular (podremos copiar un enlace a varios recursos con el botón Seleccionar en la parte superior y a través de los favoritos).
Cerrar
El apartado Recursos, si existe, abre el programa o programas asociados al recurso actual y la sección Relacionada, nos ofrece recursos similares; si pulsamos sobre uno de ellos, aparecerá un botón para retroceder, de forma que podremos navegar por los recursos encadenados.
Compartir recursos y favoritos
Podemos compartir varios recursos directamente con el botón Seleccionar, pulsando el botón Compartir selección después de seleccionar los que nos interesen.
También podemos añadir recursos a los favoritos, organizarlos en categorías y compartir la categoría completa.
Asistente de IA de NotebookLM
METAC incorpora un enlace a un cuaderno de NotebookLM que reúne la base de datos del programa junto con artículos y documentos adicionales sobre didáctica. Este asistente permite consultar la información en lenguaje natural, pedir aclaraciones, solicitar ejemplos, comparar recursos o buscar propuestas adecuadas para una necesidad concreta del aula.
Además, el cuaderno puede utilizarse directamente desde NotebookLM o incorporarse como fuente en una conversación de Gemini o en un Gem personalizado. Esto permite combinar la información organizada de METAC con materiales propios del docente, como actividades ya planificadas, para revisarlas, adaptarlas o enriquecerlas con nuevos recursos metodológicos.
Conclusión
METAC nació como una forma de ordenar metodologías activas, pero ha ido creciendo hasta convertirse en un repertorio más amplio de recursos metodológicos para el aula. Su sentido está en reunir propuestas diversas, organizarlas y relacionarlas para que resulte más fácil encontrarlas cuando aparece una necesidad concreta en la práctica docente.
Sería insensato, y contradictorio en sí mismo, pensar que es posible hacer lo que hasta ahora nunca se ha hecho por procedimientos que no sean totalmente nuevos.
 El artículo explica la metodología bayesiana para crear sistemas educativos adaptativos: cada pregunta se elige según sus respuestas anteriores, combinando el teorema de Bayes, la teoría de respuesta al ítem y la entropía de Shannon. A diferencia de los test clásicos, no exige datos de miles de alumnos ni un equipo de psicometría, sino un protocolo que cualquier docente puede ejecutar con una inteligencia artificial, ilustrado con un itinerario y un laboratorio.
El artículo explica la metodología bayesiana para crear sistemas educativos adaptativos: cada pregunta se elige según sus respuestas anteriores, combinando el teorema de Bayes, la teoría de respuesta al ítem y la entropía de Shannon. A diferencia de los test clásicos, no exige datos de miles de alumnos ni un equipo de psicometría, sino un protocolo que cualquier docente puede ejecutar con una inteligencia artificial, ilustrado con un itinerario y un laboratorio.



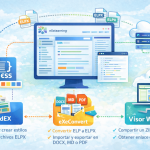


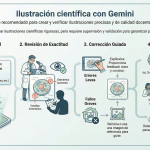















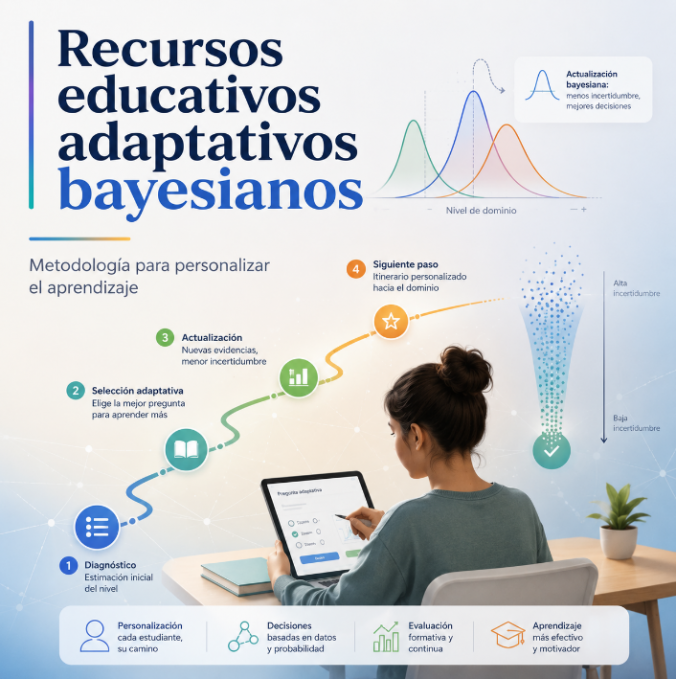
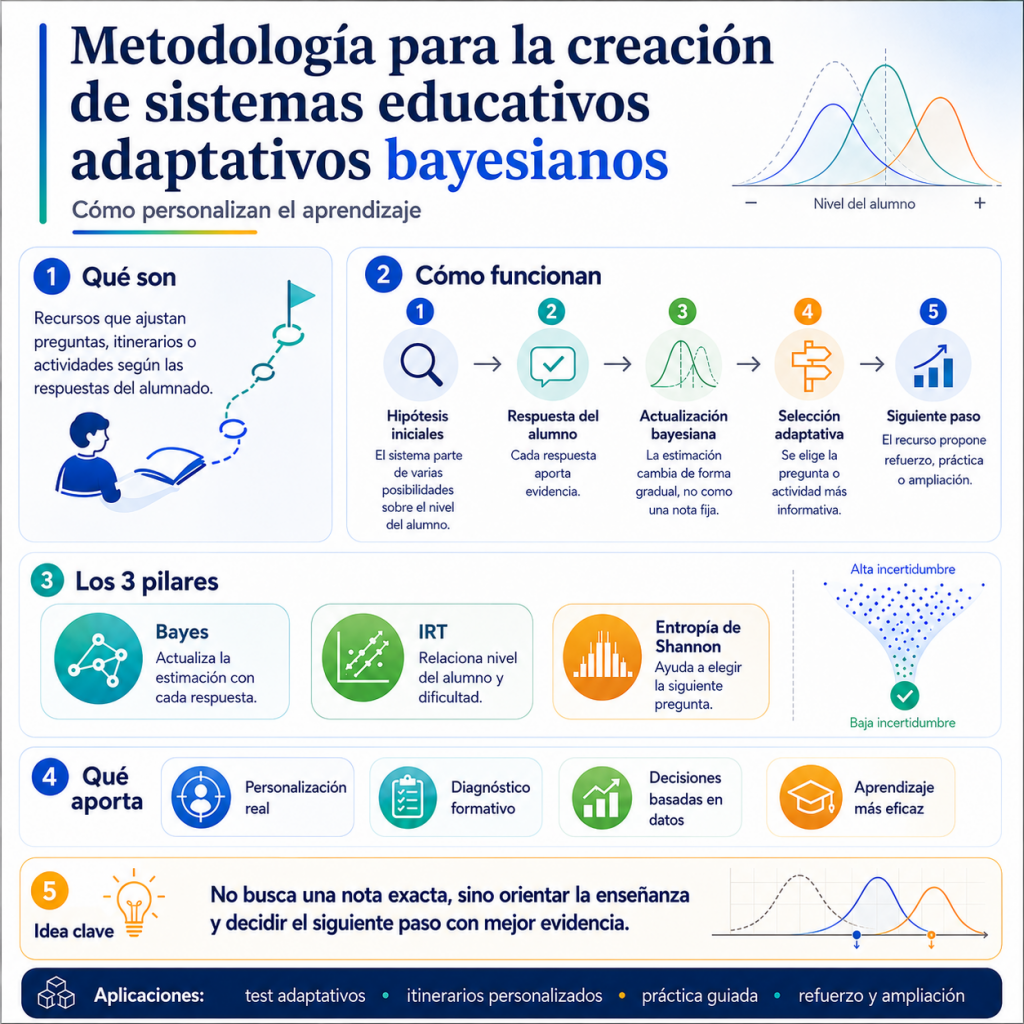
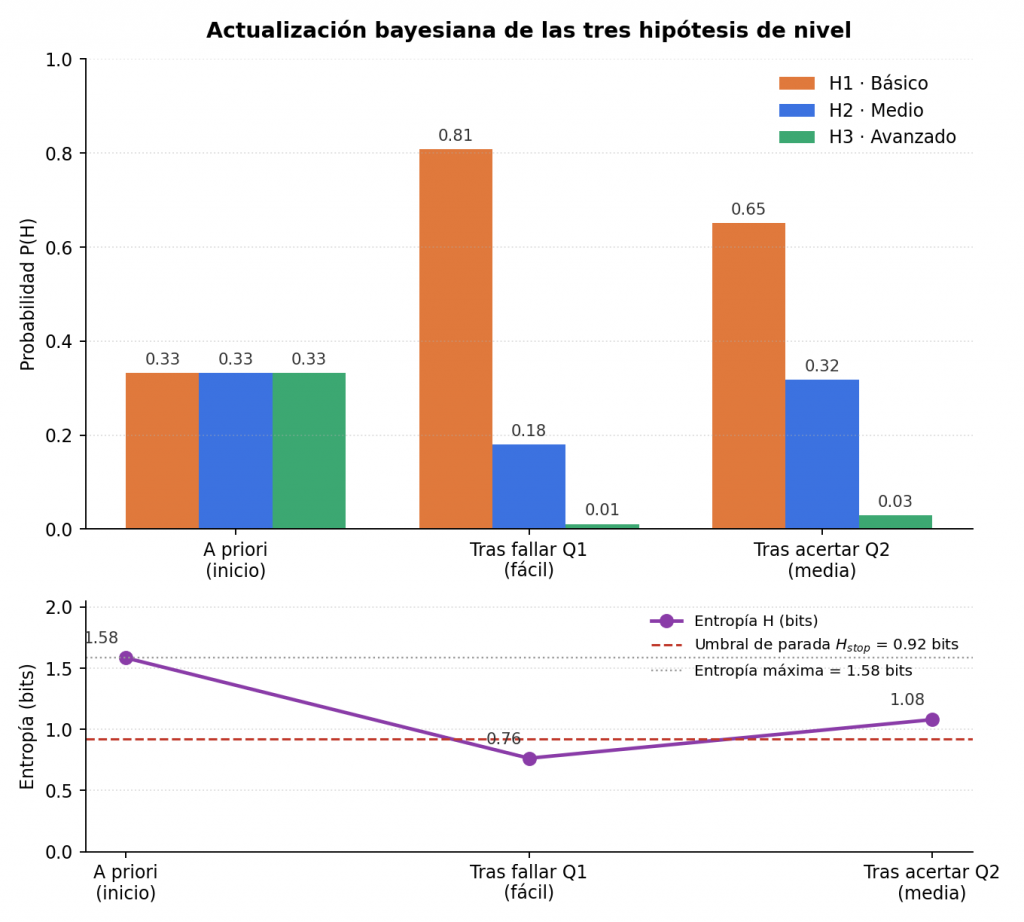
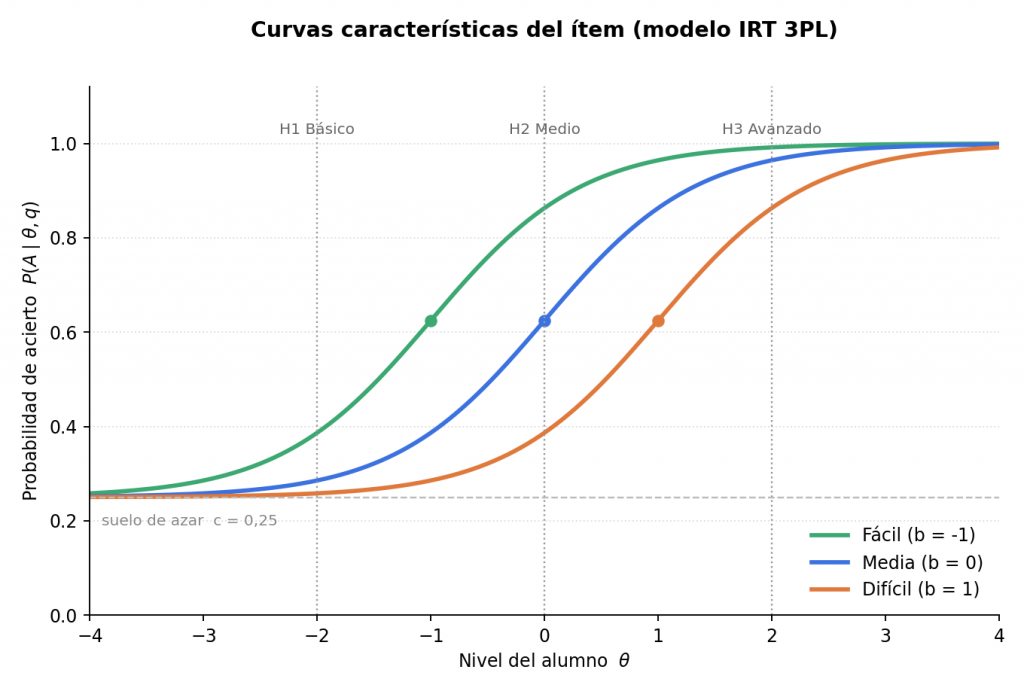

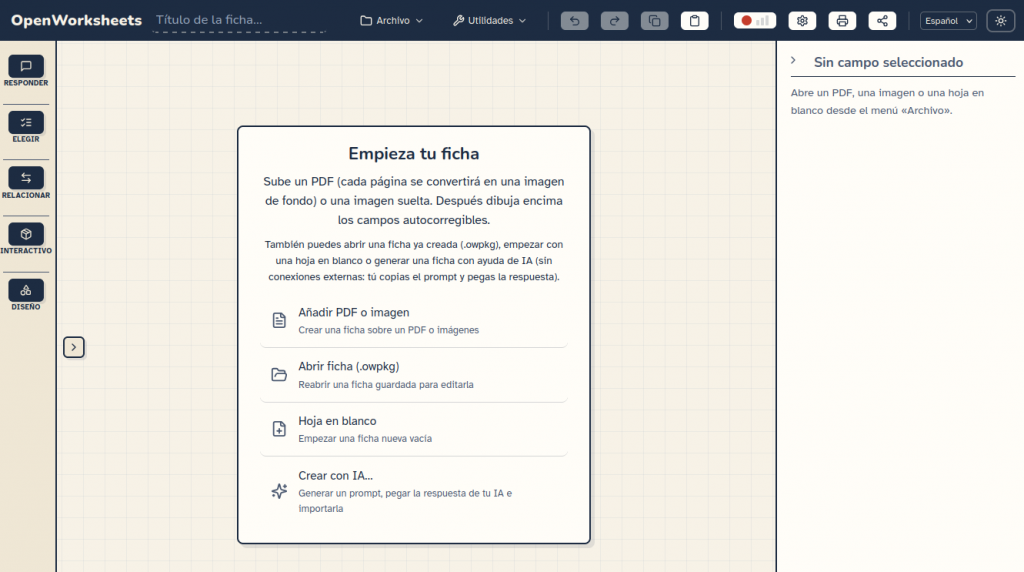
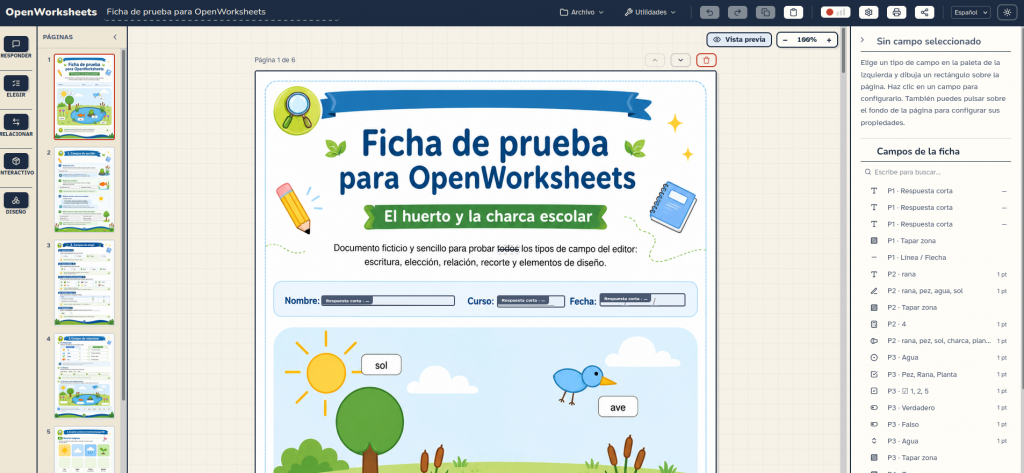
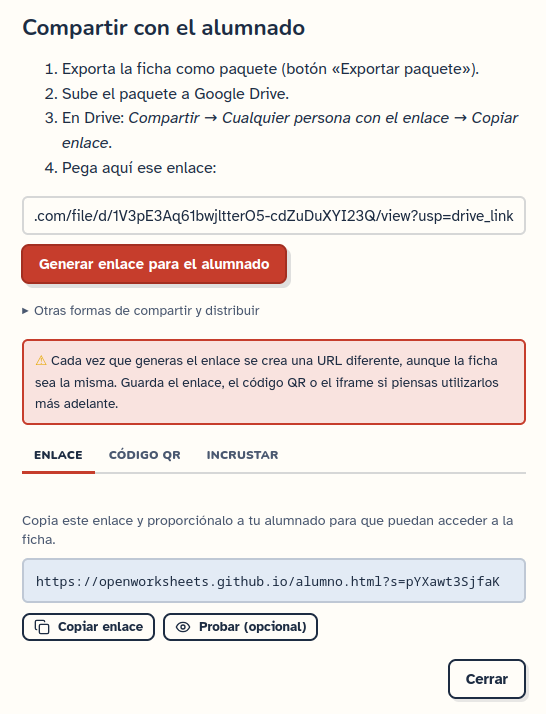
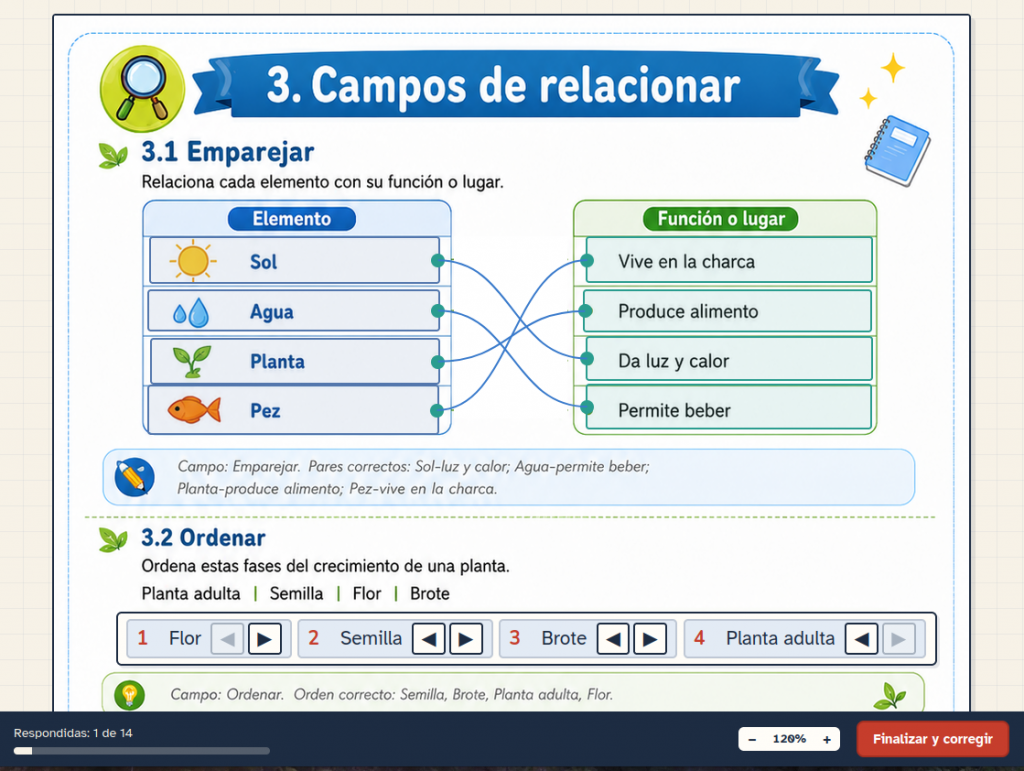
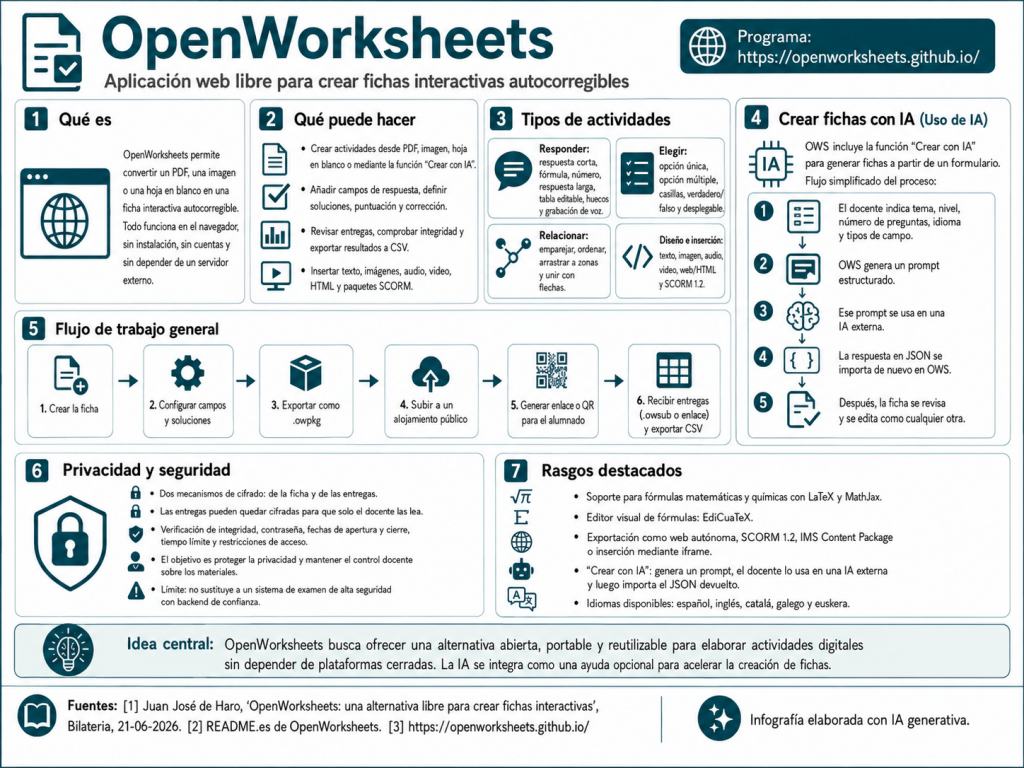



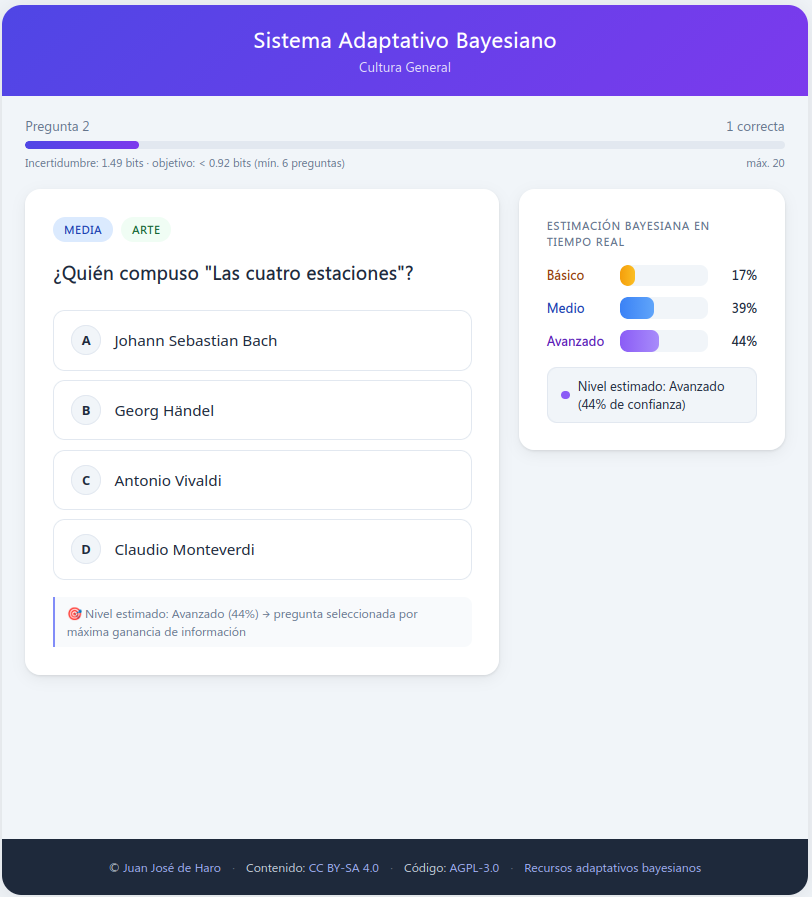
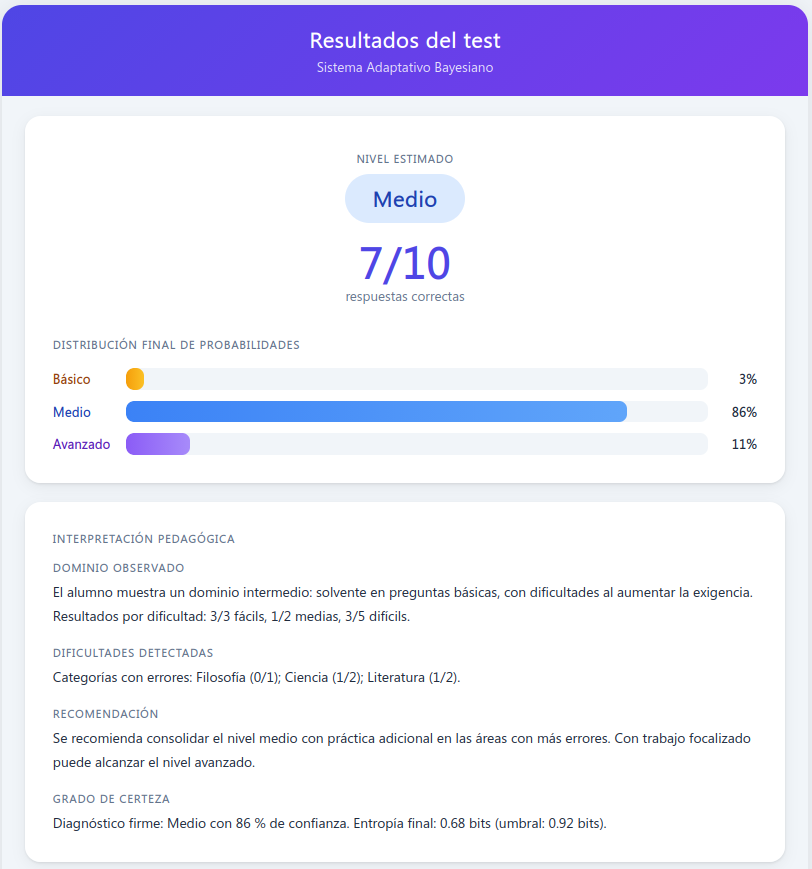
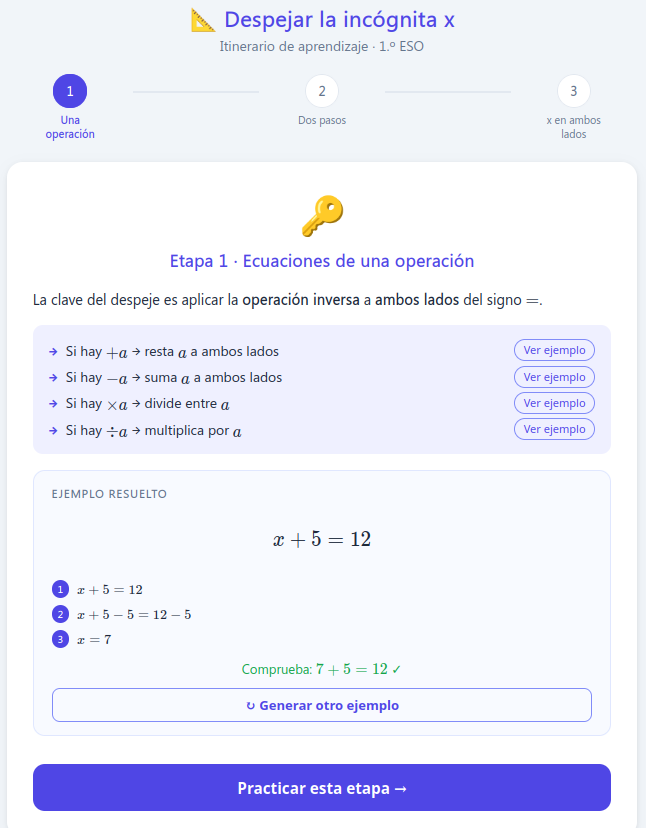
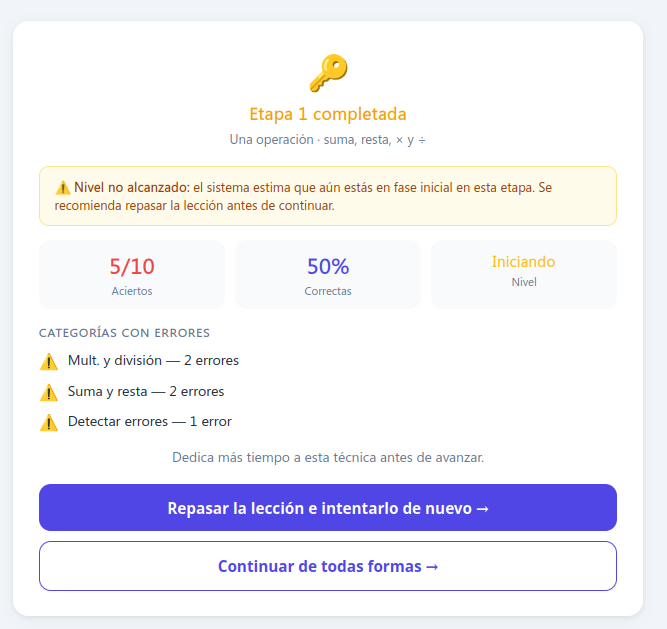
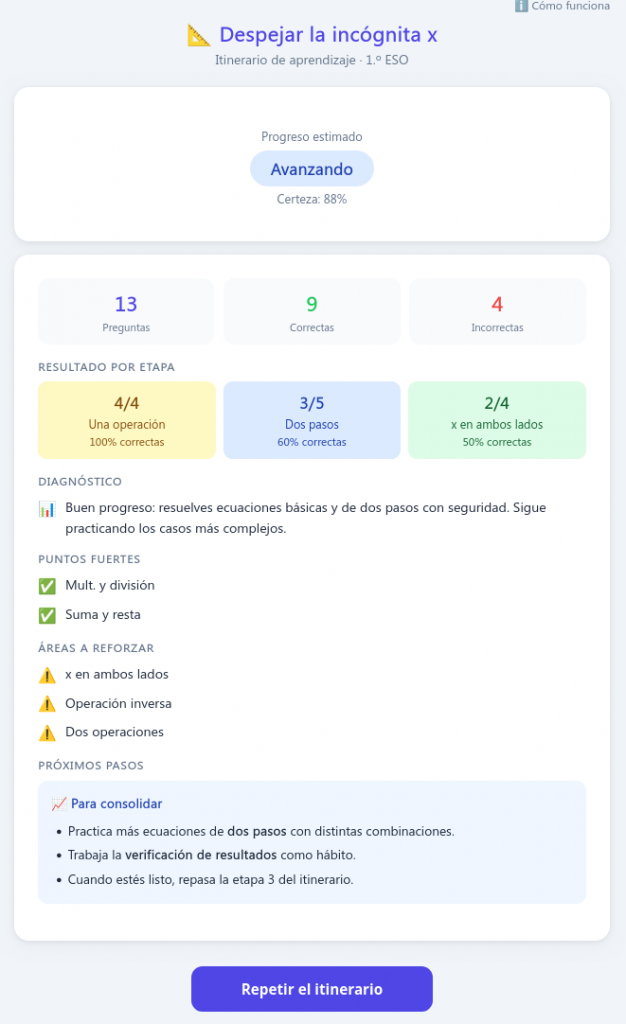

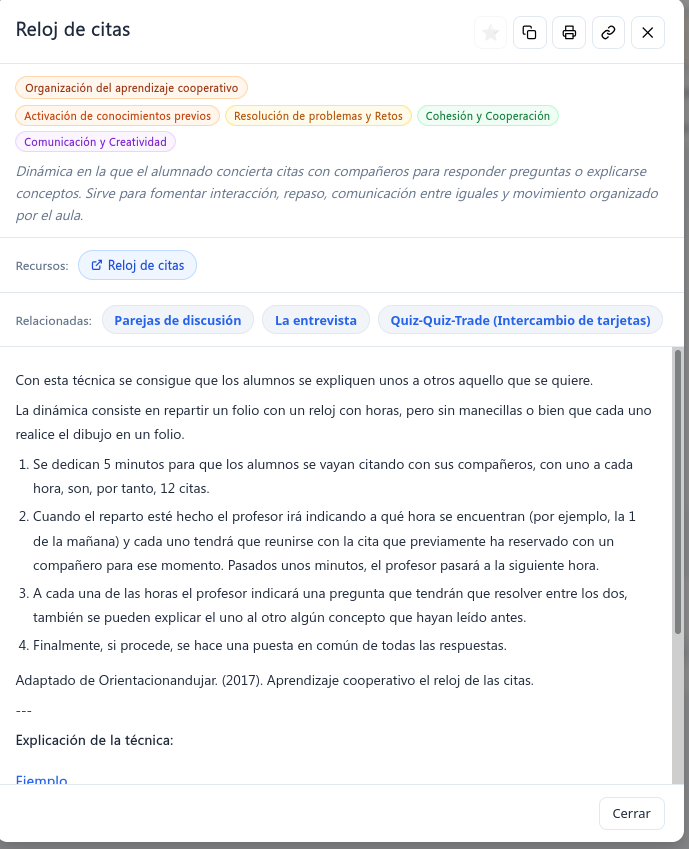









Comentarios recientes