
Entropía, Redundancia y Densidad Léxica
La riqueza y complejidad léxica de un texto son medidas importantes que pueden ayudar a los profesionales de la educación a adaptar y personalizar contenidos según las necesidades de los estudiantes. En este artículo, discutiremos las fórmulas utilizadas en nuestra herramienta de análisis de textos para calcular la entropía, redundancia y densidad léxica, así como su interpretación.
En este artículo presentamos la justificación de la herramienta:
Análisis de la riqueza y complejidad léxica de los recursos de texto: Calculadora de Entropía, Redundancia y Densidad del Léxico
Entropía (H)
La entropía es un concepto de la teoría de la información, que fue introducido por Claude Shannon en su artículo de 1948, «Una teoría matemática de la comunicación«. La entropía de Shannon es una medida cuantitativa de la incertidumbre o aleatoriedad en un conjunto de datos. En términos simples, describe la cantidad de información promedio que se necesita para identificar un resultado en un conjunto de posibles resultados.
En el contexto de la teoría de la información, la entropía se utiliza ampliamente para analizar y evaluar sistemas de comunicación, compresión de datos y criptografía. La entropía de Shannon se basa en la probabilidad de los diferentes símbolos (por ejemplo, palabras) en un mensaje o conjunto de datos. Cuanto más impredecible es la aparición de un símbolo, mayor es la entropía.
La fórmula para calcular la entropía es:
\( H = -\sum P_i \log_2(P_i) \)
Donde \( P_i \) es la probabilidad de cada palabra en el texto. Para calcular \( P_i \), se divide la frecuencia de cada palabra por el número total de palabras en el texto. La unidad de la entropía es el bit.
La entropía, en este contexto, mide la incertidumbre en el uso de palabras, reflejando la complejidad y riqueza del lenguaje en un texto. Valores altos de entropía indican mayor diversidad léxica y menor previsibilidad en las palabras, lo que sugiere un contenido más complejo y rico. Valores bajos señalan un contenido más simple y limitado, con mayor repetición y menor variabilidad en el vocabulario.
Redundancia (R)
La redundancia es una medida de la repetitividad en un texto. Cuanto mayor sea la redundancia, más repetitivas y menos informativas serán las palabras. La fórmula para calcular la redundancia es:
\( R = H_{max} – H \)
La entropía máxima \(( H_{max} )\) se calcula utilizando la fórmula:
\( H_{max} = \log_2(N) \)
Donde N es el número de palabras únicas en el texto. La unidad de R es el bit.
Densidad Léxica (DL)
La densidad léxica es una medida de la diversidad de palabras en un texto y también recibe el nombre de TTR (Type Token Ratio). Se calcula dividiendo el número de palabras distintas por el número total de palabras en el texto:
\(DL = \frac{Número \ de \ palabras \ distintas}{Número \ total \ de \ palabras} \)
No tiene unidades, ya que se trata de una proporción.
Densidad Léxica Estandarizada (DLE)
El método utilizado para calcular la Densidad Léxica Estandarizada proviene de la rarefacción, que es un método estadístico que se origina en la biología, donde se utiliza para evaluar la diversidad de especies en un ecosistema. En el estudio de la biodiversidad, la rarefacción es un método que permite comparar la riqueza de especies entre diferentes hábitats o comunidades, normalizando el tamaño de las muestras. De esta manera, es posible comparar la diversidad de especies en diferentes entornos sin que los resultados se vean afectados por el tamaño de la muestra.
En el análisis del lenguaje, la Densidad Léxica Estandarizada es una medida que hemos utilizado para evaluar la riqueza y diversidad léxica en un texto. Al igual que en la biología, el objetivo es obtener una medida de la diversidad léxica que sea comparable entre diferentes textos, independientemente de la cantidad de palabras en cada uno de ellos. Hemos usado la DLE como un método alternativo para hallar la densidad léxica.
La densidad léxica estandarizada es una medida que tiene en cuenta el tamaño del texto y proporciona una estimación de la densidad (diversidad) de palabras en una muestra de tamaño fijo.
El método para hallar la densidad léxica estandarizada se lleva a cabo de la siguiente manera:
- Se realizan 1000 muestreos, cada uno con 100 palabras seleccionadas al azar. Cada uno de estos 1000 muestreos es independiente de los demás, lo que significa que algunas palabras podrían aparecer en diferentes muestreos. No obstante, dentro de cada muestra individual de 100 palabras, no hay repeticiones.
- Para calcular la Densidad Léxica Estandarizada, se divide el número de palabras diferentes (únicas) en cada muestra por el total de palabras en esa muestra, que en este caso es 100. Al hacer esto, se obtiene un porcentaje que representa la diversidad léxica en una muestra específica.
- Después de calcular la DLE para cada una de las 1000 muestras, se hace la media de todas las DLE individuales. Este promedio representa la densidad léxica general en el texto, considerando la variación entre las diferentes muestras. Esta medida proporciona una estimación más precisa de cuán variado y enriquecido es el lenguaje utilizado en el texto completo.
La fórmula utilizada para calcular la densidad léxica estandarizada es la siguiente:
\( DLE = \frac{\displaystyle\sum_{i=1}^{1000} \frac{\text{Palabras Distintas en Muestra}_{i}}{100}}{1000} \)
Donde: \(\text{Palabra Distinta de Muestra}_{i}\) es el número de palabras distintas en cada muestra que está formada por 100 palabras
Este proceso permite estandarizar la diversidad léxica entre textos de diferentes longitudes y proporciona una medida más robusta de la densidad.
Dado que se toman muestras de 100 palabras, cuando el texto introducido tiene 100 o menos palabras, la DLE coincide con la densidad léxica. No tiene unidades, ya que se trata de una proporción.
Interpretación de los resultados
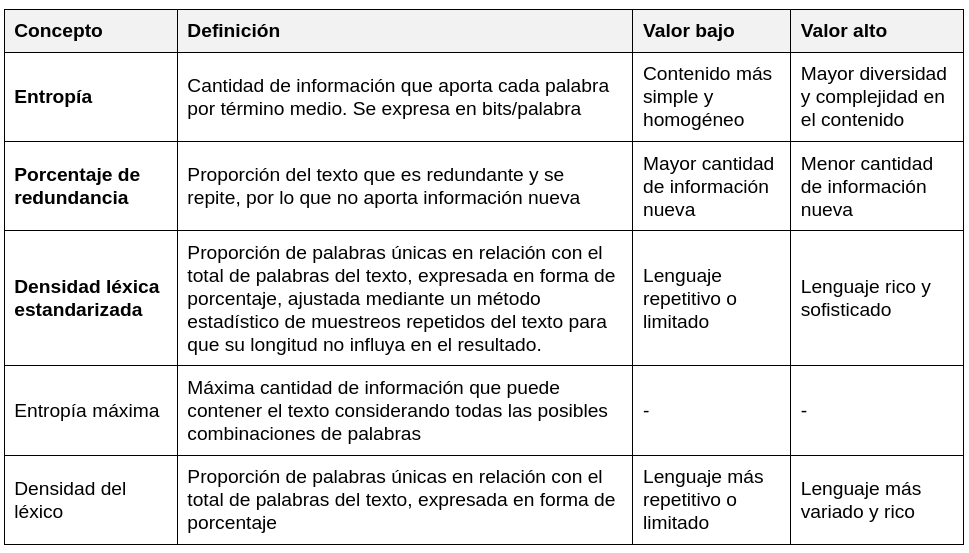
Los rangos seleccionados en la tabla de interpretación de entropía, densidad léxica estandarizada y redundancia están basados en observaciones generales y patrones identificados en diferentes tipos de textos y niveles educativos. Estos rangos tienen como objetivo proporcionar un marco de referencia para la interpretación de los resultados obtenidos al analizar un texto.
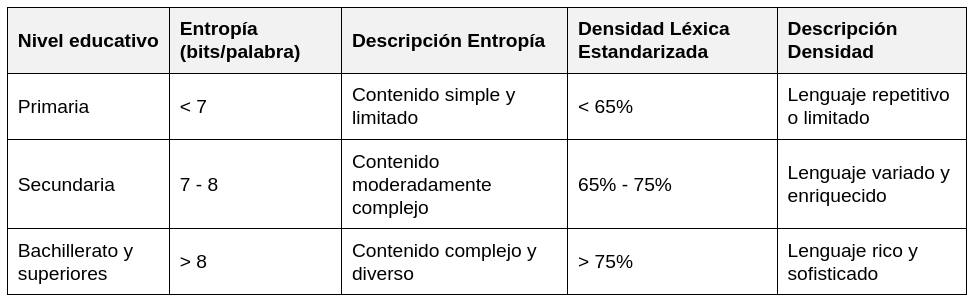
Para la entropía y la densidad léxica estandarizada, los rangos se han establecido teniendo en cuenta la complejidad del contenido y el vocabulario utilizado en textos de nivel primaria, secundaria y bachillerato o superiores. Estos rangos pueden variar según el tema y el estilo de escritura de cada autor, pero proporcionan una referencia aproximada para evaluar la complejidad y diversidad del contenido en función del nivel educativo.
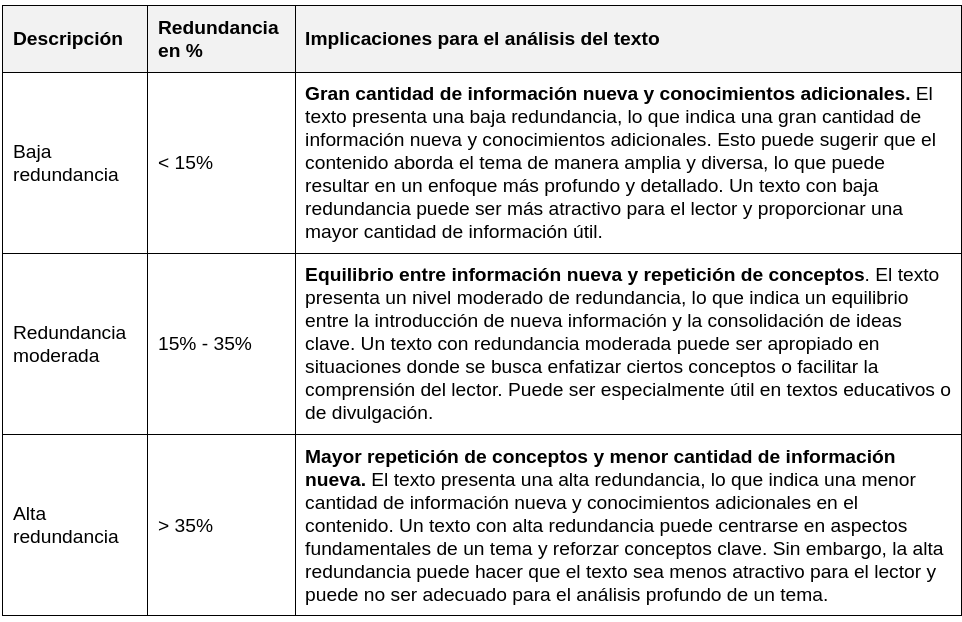
En cuanto a la redundancia, los rangos se han determinado para ayudar a identificar el grado en el cual un texto presenta información nueva o conocimientos adicionales. Un porcentaje más bajo de redundancia indica una mayor cantidad de información nueva, mientras que un porcentaje más alto sugiere una mayor repetición de conceptos y menor cantidad de información nueva.
Estos rangos no son absolutos y pueden variar según el tema y el estilo de escritura de cada persona, así como el tipo de texto (por ejemplo, literatura, ensayos científicos, textos divulgativos, etc.). Además, proporcionan una referencia aproximada para la interpretación de las métricas y no deben ser considerados como límites estrictos.
Interpretación de la entropía y la densidad léxica estandarizada según niveles educativos
Redundancia
Interpretación de las métricas
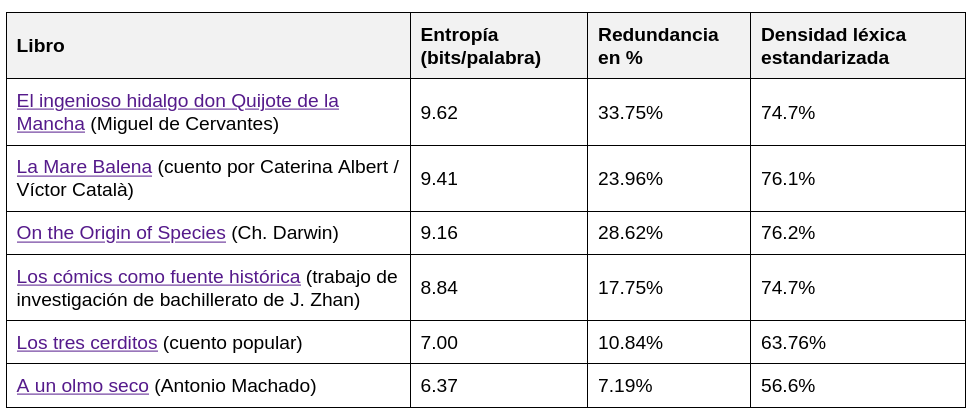
Ejemplos con diferentes fuentes
Fuentes consultadas
- Capsada Blanch, R., & Torruella Casañas, J. (2017). Métodos para medir la riqueza léxica de los textos. Revisión y propuesta. Verba: Anuario galego de filoloxia, 44.
- Kraker-Castañeda, C., & Cóbar-Carranza, A. J. (2011). Uso de rarefacción para la comparación de la riqueza de especies: el caso de las aves de sotobosque en la zona de influencia del Parque Nacional Laguna Lachuá, Guatemala. Naturaleza y Desarrollo, 9(1), 60-70.
- Morales, H. L. (2011). Los índices de riqueza léxica y la enseñanza de lenguas. In Del texto a la lengua: La aplicación de los textos a la enseñanza-aprendizaje del español L2-LE (pp. 15-28). Asociación para la Enseñanza del Español como Lengua Extranjera-ASELE.
- OpenAI. (2023). ChatGPT–4 (versión 23 de marzo).
- Riffo, K. F., Osuna, S. H., & Lagos, P. S. (2019). Descripción de la diversidad y densidad léxicas en noticias escritas por estudiantes de periodismo. Revista Brasileira de Linguística Aplicada, 19, 499-528.









Comentarios recientes