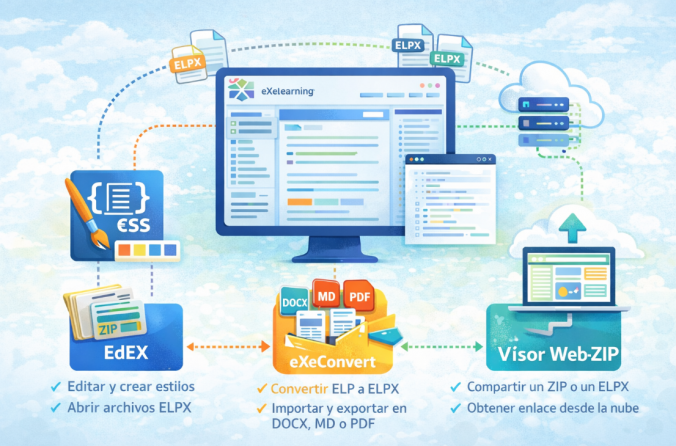

eXeLearning es un programa de software libre para crear recursos educativos. Nos permite añadir texto, imágenes, audio, vídeo y dispone de un completo conjunto de recursos interactivos. Además, podemos insertar cualquier recurso creado fuera de eXeLearning gracias a su gestor de archivos, capaz de albergar cualquier objeto digital, y a la capacidad que tiene eXeLearning para insertarlos, aunque estén fuera del propio recurso.
Los proyectos (nombre que se da a los archivos creados con eXe, que tienen extensión ELPX) se pueden también exportar como página web (nos dará un archivo ZIP con la web en su interior), SCORM 1.2 (utilizado por programas educativos como Moodle), ePub (para libros electrónicos) y también como página única (todo el proyecto en una única página).
Hemos hecho tres aplicaciones que ofrecen apoyo al programa:
- EdEX para crear y editar estilos.
- eXeConvert, para exportar e importar entre diversos formatos (ELP, DOCX, MD, PDF) con el ELPX como centro.
- Visor Web-ZIP para publicar y compartir fácilmente los proyectos creados con eXeLearning.
- ELPX Translator Desktop para traducir mediante el uso de la IA los proyectos ELPX.

EdEX
EdEX es un editor de estilos que permite utilizar diversas fuentes:
- Por defecto, aparece un ejemplo cargado con el estilo base de eXeLearning. Podemos empezar a modificarlo o seleccionar cualquiera del resto de estilos que vienen con eXeLearning.
- Cargar un estilo en formato ZIP de cualquier versión.
- Cargar un archivo ELPX y trabajar directamente con él y el estilo que lleva incorporado. Podremos extraer el estilo por separado y volver a guardar el ELPX que lo incorporará.
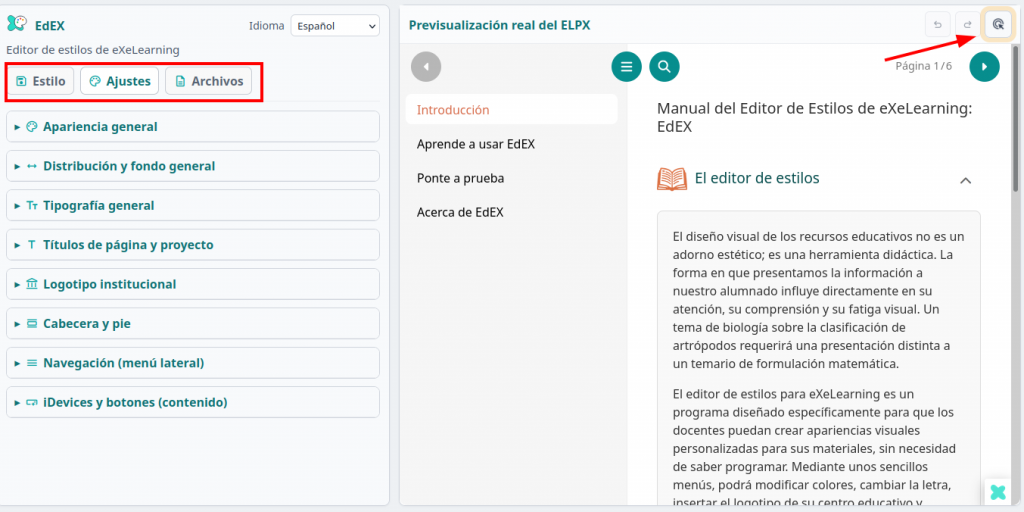
Una vez que comencemos a modificarlo, podremos hacerlo a través de las pestañas que hay en el panel izquierdo o pulsando el botón para cambiar a modo edición por clic (el botón que hay en la esquina superior derecha).

eXeConvert
eXeConvert permite convertir entre diferentes formatos, donde el ELPX es el formato central.
- ELP. Es el formato de las versiones anteriores. Cualquier ELP cargado en el programa es automáticamente convertido en ELPX que podremos guardar en el ordenador o convertirlo en DOCX, MD o PDF.
- DOCX. Podemos exportar el ELPX hacia DOCX, pero también importar el DOCX para generar un ELPX. Los diferentes niveles de encabezados definen las páginas, subpáginas y los iDevices.
- En el caso ELPX -> DOCX, se crearán los encabezados siguiendo la pauta: Los títulos de las páginas se convertirán en encabezado 1, los de las subpáginas en encabezado 2, las subpáginas de las subpáginas, encabezado 3, etc. Los títulos de los iDevices serán los próximos encabezados no usados (el 2, 3, …). Los encabezados propios que ya lleven los iDevices se adaptan a esta estructura descendente, hasta un máximo de 6 niveles.
- Para el caso opuesto DOCX -> ELPX se sigue el mismo proceso, pero el usuario decide cuántos niveles de páginas habrá.
- MD. Corresponde al formato Markdown. Se pueden insertar las imágenes, o no, en el texto, aunque no es aconsejable sin un motivo concreto, ya que se codifican en base64 y el archivo quedará lleno de caracteres no legibles. Exportar en este formato es muy útil para extraer únicamente el texto con un formato bien definido. Se siguen las mismas reglas de importación/exportación con encabezados que en el formato DOCX.
- PDF. El ELPX se puede guardar en formato PDF.
Cuando exportemos a DOCX, MD o PDF, podremos elegir qué páginas queremos exportar: todas o solo alguna.

Sugerencia: Podemos crear la estructura de un recurso en Markdown utilizando una IA y diciéndole que utilice encabezados para los diferentes niveles del índice. Al convertir en ELPX este archivo, obtendremos la estructura completa de páginas y subpáginas de una forma muy sencilla.

Visor Web-ZIP
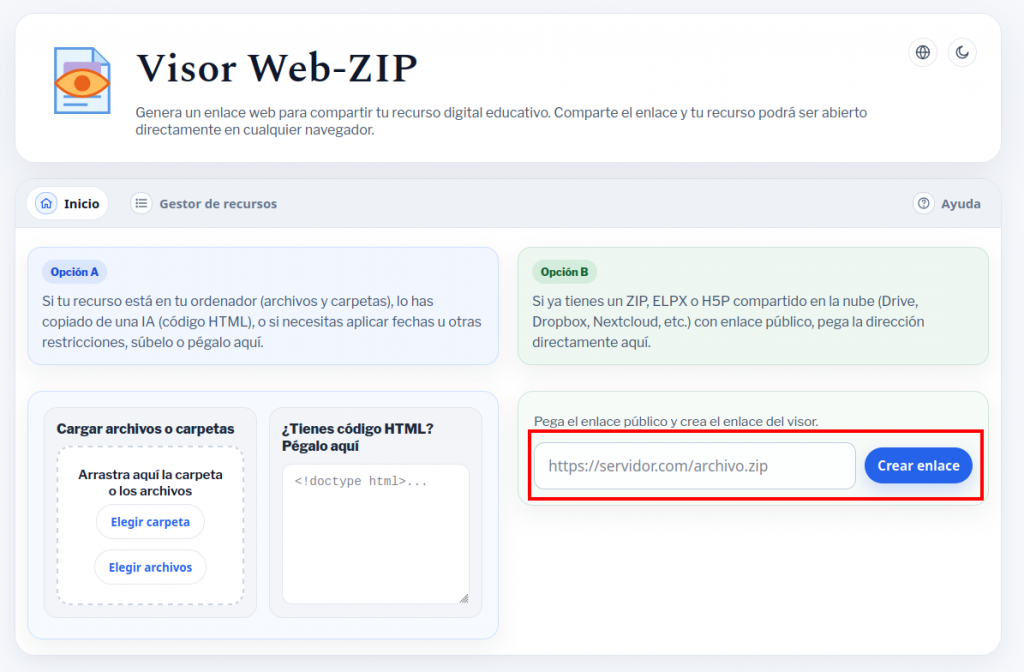
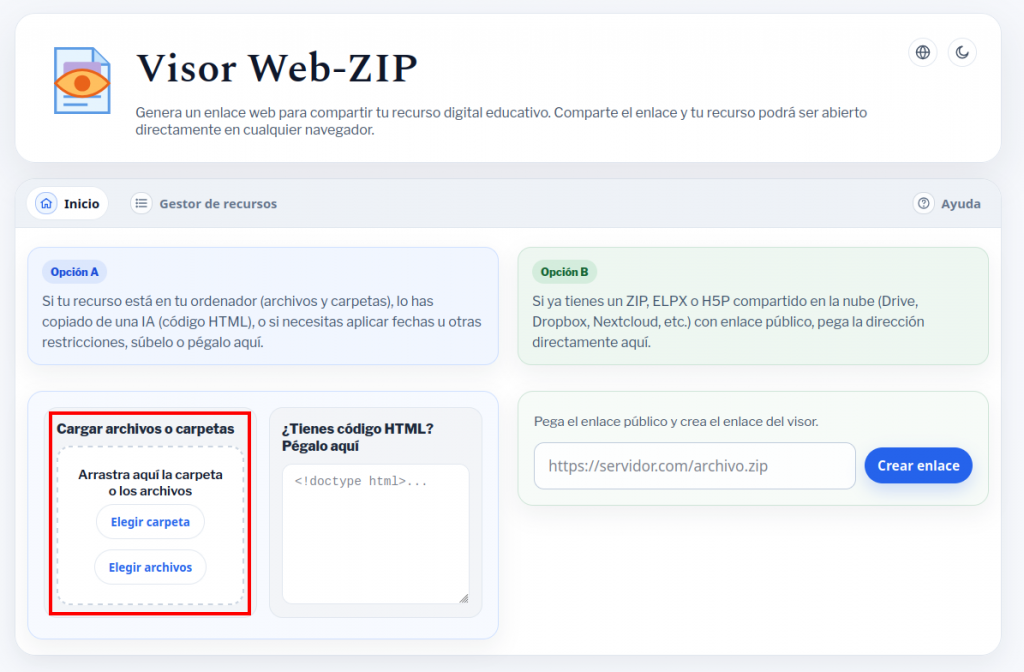
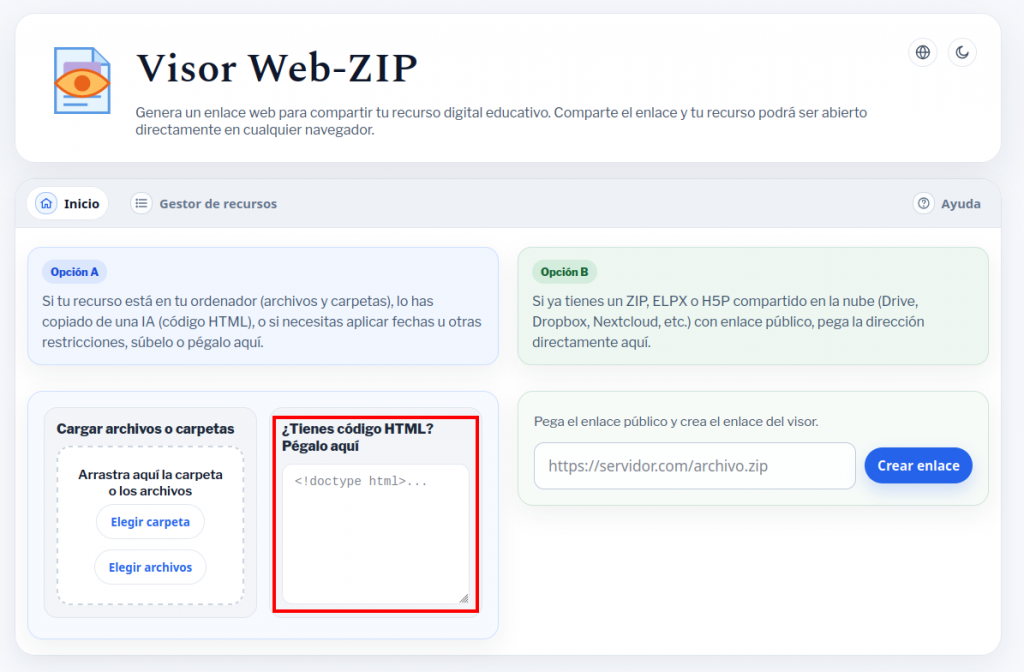
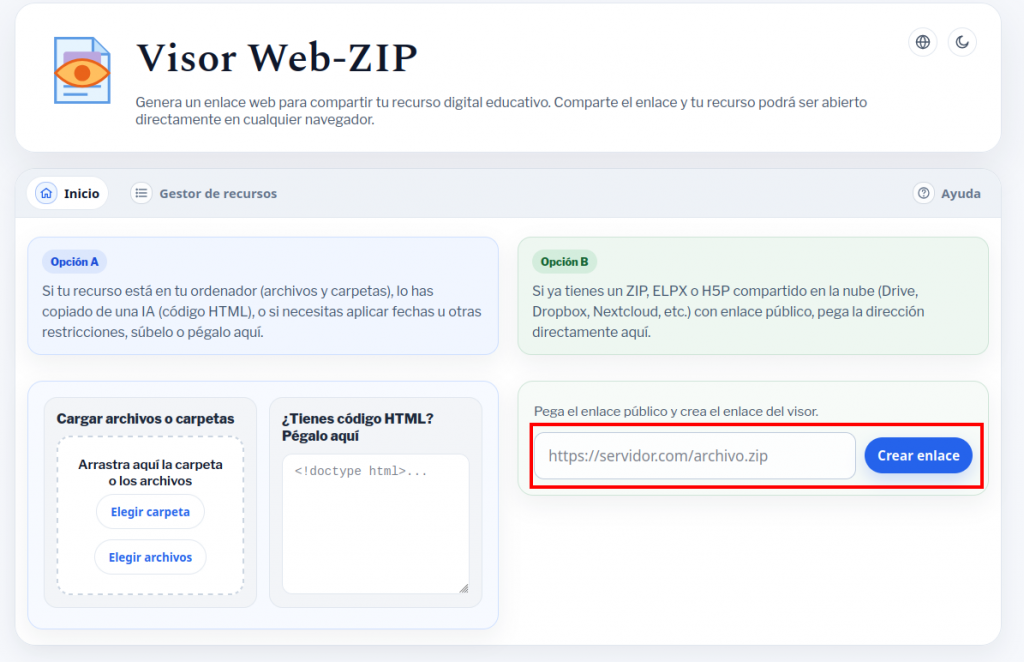
Visor Web-ZIP es un programa que nos permite publicar y compartir un ELPX o un proyecto exportado en ZIP (de cualquier versión de eXeLearning) simplemente subiendo a Drive, Dropbox, Nextcloud, Box.com o un sistema similar el archivo.
Visor Web-ZIP en realidad permite publicar cualquier recurso digital y para ello dispone de varios visores. Puedes obtener más información sobre esto último en el artículo: Visor Web-ZIP: Publica y comparte tus recursos educativos desde tu almacenamiento favorito en la nube.
Para publicar un ELPX o un proyecto exportado como página web en ZIP, únicamente necesitamos:
- Subir el archivo a un sistema de almacenamiento en la nube y compartirlo para que todos puedan verlo (Google Drive solo permite archivos de unos 25MB, si nuestro recurso ocupa más, habrá que utilizar otro servicio).
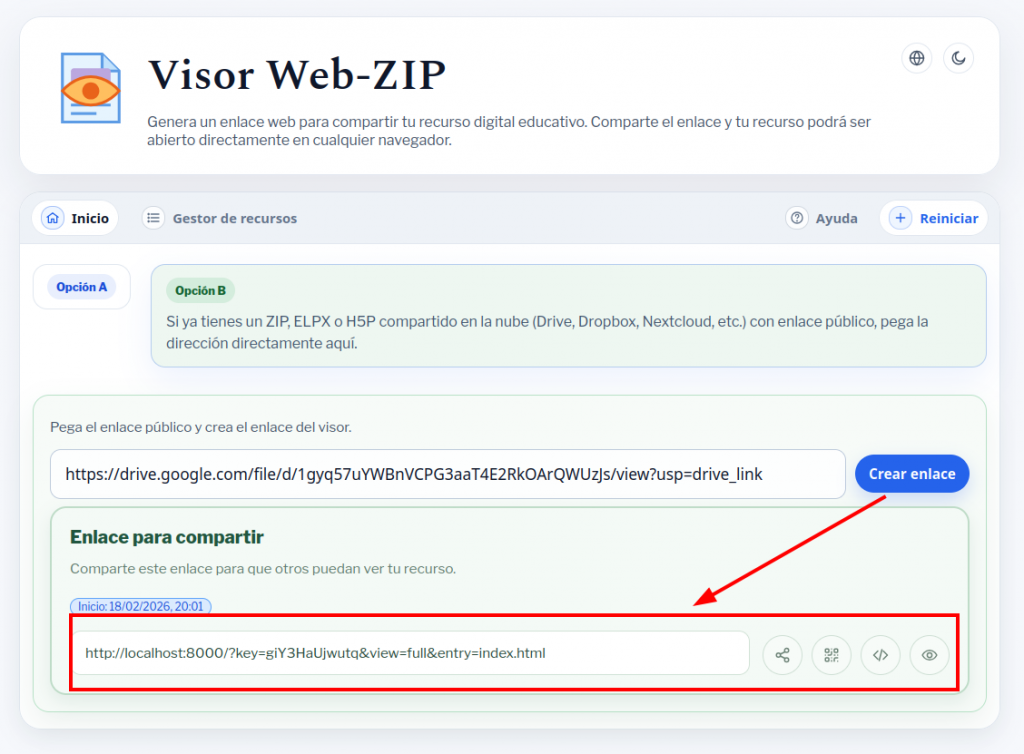
- Pegar el enlace para compartir que hemos obtenido en la nube en la sección 2 del programa y copiar el enlace que nos proporciona. Con ese enlace cualquiera podrá ver en su navegador nuestro proyecto.
Se pueden poner fechas de apertura y cierre de visualización del recurso. Véase el artículo anterior para saber cómo hacerlo.
En la siguiente presentación se explica con más detalle el proceso, incluyendo los límites de distintos servicios y cómo subir archivos de hasta 2GB para compartir.
Actualización: Actualmente está diposnible eXeViewer, un visor de archivos ELPX y ZIP de eXeLearning que permite publicar los contenidos de forma similar a Visor WebZIP. No obstante, presenta problemas cuando los archivos se alojan en Dropbox o Nextcloud.
ELPX Translator Desktop
A diferencia del resto de programas, este no es una página web, sino una aplicación que debe ser instalada en el ordenador local. El motivo es que, al hacer uso de un modelo de traducción de IA, los requerimientos de cálculo son demasiado exigentes para ser llevados a cabo por un navegador.
Hay dos versiones para Linux (una para derivados de Debian y una AppImage), una para Windows y otra para macOS.
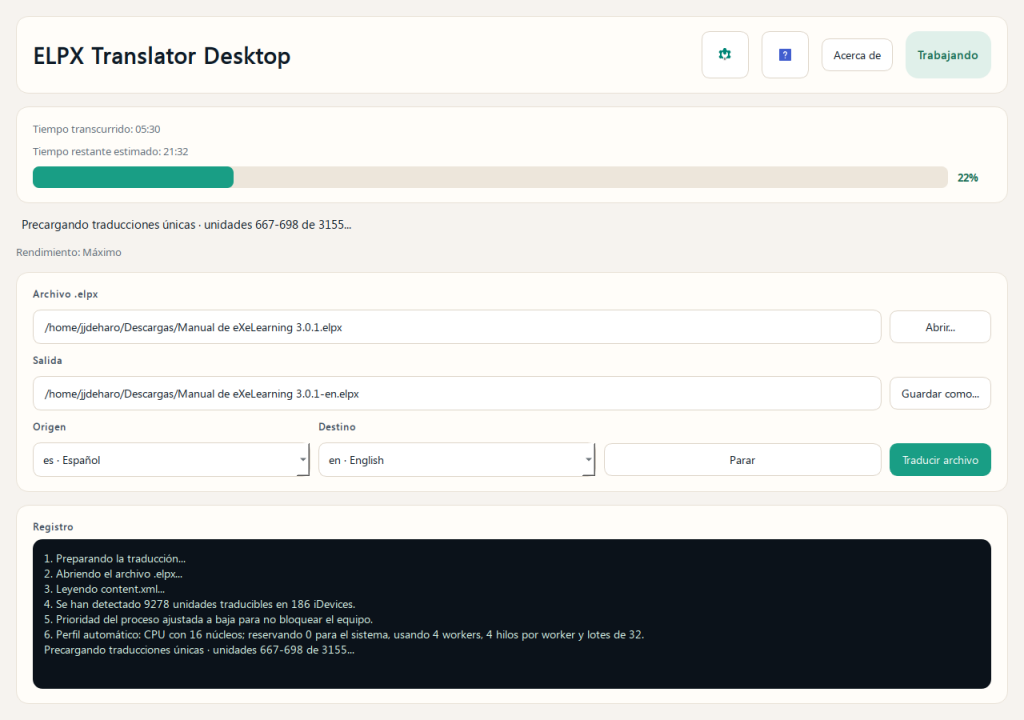
El funcionamiento es bien sencillo. Se indica qué archivo ELPX se quiere traducir, se elige el idioma al que se traducirá y se pulsa el botón Traducir.
Se utilizan modelos de código abierto que se ejecutan en local, por lo tanto, no se envían datos a ningún lado. M2M100 418M de Meta para todos los idiomas, excepto euskera y OPUS-MT, que es de la Universidad de Helsinki (Helsinki-NLP), para euskera.
Más información y descargas en la página web del proyecto ELPX Translator Desktop.
Nota: El texto de este artículo tiene nivel 0 en el Marco para la integración de la IA generativa.





















Comentarios recientes