Este artículo describe los fundamentos básicos de la metodología utilizada para crear recursos educativos que se adaptan a las respuestas del alumno. Puedes ver ejemplos aquí:
- Test adaptativo de cultura general. Una prueba sencilla para comprobar la evaluación adaptativa.
- Itinerario para aprender a despejar la incógnita x. Ejercicios con ecuaciones de primer grado para probar los itinerarios de aprendizaje adaptativos.
- Laboratorio de combinatoria (sección: Práctica – Resuelve problemas). Ejercicios de combinatoria para aprender y comprobar la multidimensionalidad del modelo, donde no solo se evalúan conocimientos, sino también habilidades transversales de forma adaptativa.
- ¿Cómo comparas los decimales? Un recurso adaptativo que no solo comprueba si el alumno acierta o falla al comparar decimales, sino que intenta averiguar qué tipos de errores conceptuales hay detrás de sus respuestas. Es un ejemplo de evaluación de ítems no ordenados (cada error conceptual es independiente de los otros)
Si lo que quieres es implantarlo mediante IA en algún recurso nuevo o que ya tengas hecho, en la web Recursos educativos adaptativos tienes un archivo para adjuntar a la IA de forma que sepa cómo debe actuar para crear una página web con el recurso adaptativo.
Tabla de contenidos
Planteamiento general de la metodología
Una actividad fija, sea una prueba, un ejercicio o cualquier otro recurso, plantea las mismas preguntas, en el mismo orden, a todo el alumnado, sin tener en cuenta su nivel de partida: mide, pero no se ajusta a quien la responde. La metodología que se describe en este artículo resuelve esa limitación haciendo que cada pregunta dependa de las respuestas anteriores dadas por el alumno. A lo largo del texto se utilizan como ejemplos tres recursos construidos con ella (un test adaptativo de cultura general, un itinerario para aprender a despejar la incógnita x y un laboratorio de combinatoria); son solo ejemplos y la metodología no se limita a esos tres casos y puede aplicarse a cualquier materia o formato. El teorema de Bayes, la teoría de respuesta al ítem y la entropía de Shannon, que se utilizan, ya existen por separado desde hace décadas en la literatura de medición educativa; lo que aporta esta metodología es la forma de combinarlos y, sobre todo, que todo el procedimiento está escrito como un protocolo reproducible que una inteligencia artificial puede ejecutar para generar un recurso nuevo en cualquier materia, sin equipo de psicometría ni datos de miles de alumnos.
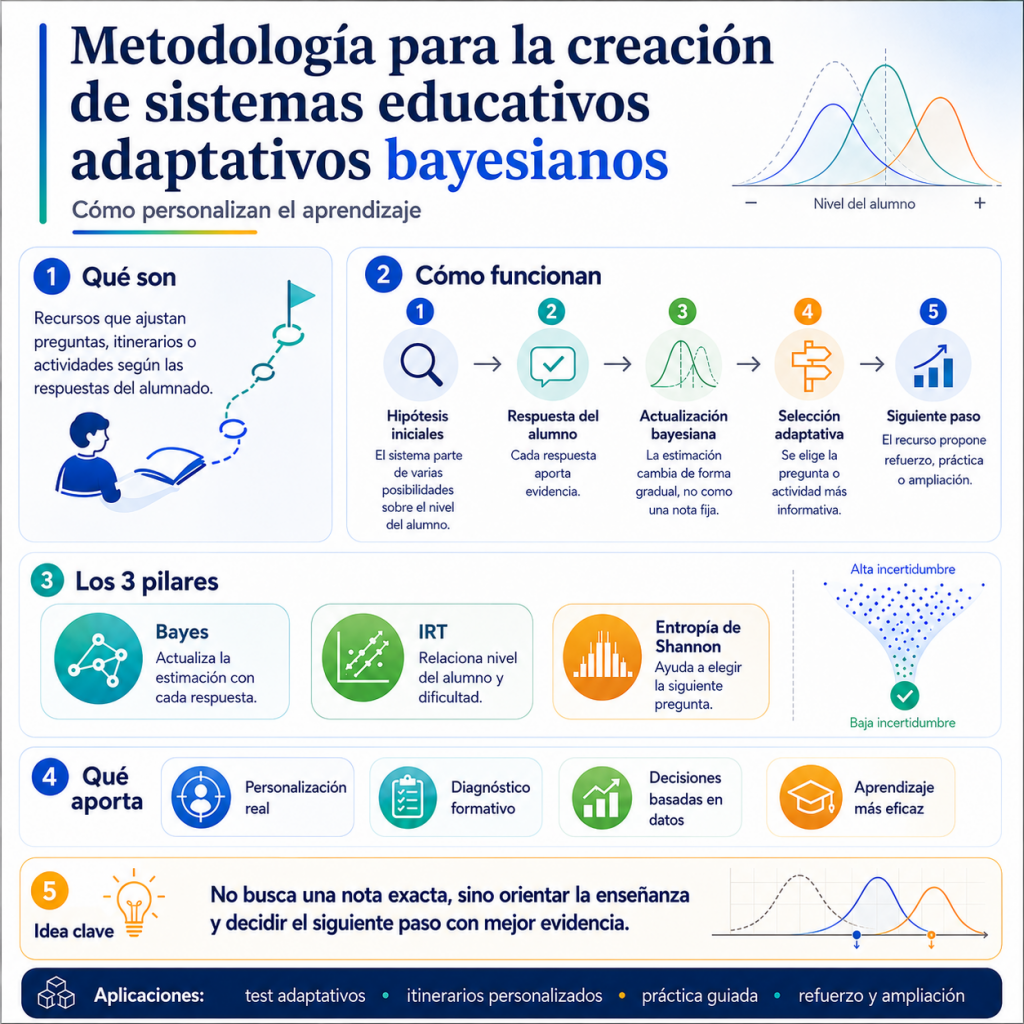
Representación probabilística del estado del alumno
El sistema no calcula una nota al final del proceso, sino que mantiene una distribución de probabilidad sobre varias hipótesis de nivel del alumno, por ejemplo, tres hipótesis sobre su nivel: H1 (básico), H2 (medio) y H3 (avanzado), cada una con un valor asociado de habilidad θ (theta).
Al empezar, el sistema no sabe nada del alumno, así que reparte la probabilidad de pertenencia a un nivel en partes iguales: P(H1) = P(H2) = P(H3) = 0,33. A medida que el alumno responde preguntas, esa probabilidad se va desplazando hacia la hipótesis que mejor explica lo que está ocurriendo. Nunca hay un único número que resuma al alumno, sino una distribución completa de lo probable y lo improbable en ese momento, lo que permite representar también la duda: un alumno con un patrón de respuestas contradictorio queda reflejado como una probabilidad repartida entre varias hipótesis, en vez de forzarlo a encajar en una etiqueta.
Actualización bayesiana de las hipótesis de nivel
El mecanismo que desplaza esa probabilidad entre diferentes niveles al responder se llama actualización bayesiana, y se apoya directamente en el teorema de Bayes:
$$P(H_i \mid r) = \frac{P(r \mid H_i) \cdot P(H_i)}{\sum_j P(r \mid H_j) \cdot P(H_j)}$$
El significado de cada término es el siguiente.
- \(P(H_i \mid r)\) es la probabilidad a posteriori: la probabilidad de la hipótesis \(H_i\) (por ejemplo, «nivel avanzado») una vez conocida la respuesta r del alumno. Es el resultado que interesa, la creencia ya actualizada tras una respuesta.
- \(P(H_i)\) es la probabilidad a priori: la probabilidad que se le daba a esa misma hipótesis antes de conocer la respuesta.
- \(P(r \mid H_i)\) es la verosimilitud: la probabilidad de que se produjera esa respuesta concreta si la hipótesis \(H_i\) (el nivel de habilidad que se está evaluando, por ejemplo, «nivel avanzado») fuera cierta. La calcula el modelo de respuesta al ítem que se describe en la sección siguiente.
- \(\sum_j P(r \mid H_j) \cdot P(H_j)\) es el término de normalización: la suma de esa misma cantidad para todas las hipótesis, que garantiza que las probabilidades finales sumen 1 y no tiene otra función que esa.
La fórmula dice que la nueva creencia sobre cada hipótesis (la probabilidad a posteriori, \(P(H_i \mid r)\)) es proporcional a dos cosas: lo bien que esa hipótesis explica la respuesta que se acaba de observar (la verosimilitud, \(P(r \mid H_i)\)) y la creencia que ya se tenía sobre ella (la probabilidad a priori, \(P(H_i)\)). Las hipótesis que hacían más probable la respuesta observada ganan peso; las que la hacían improbable lo pierden.
Ejemplo numérico del proceso de actualización
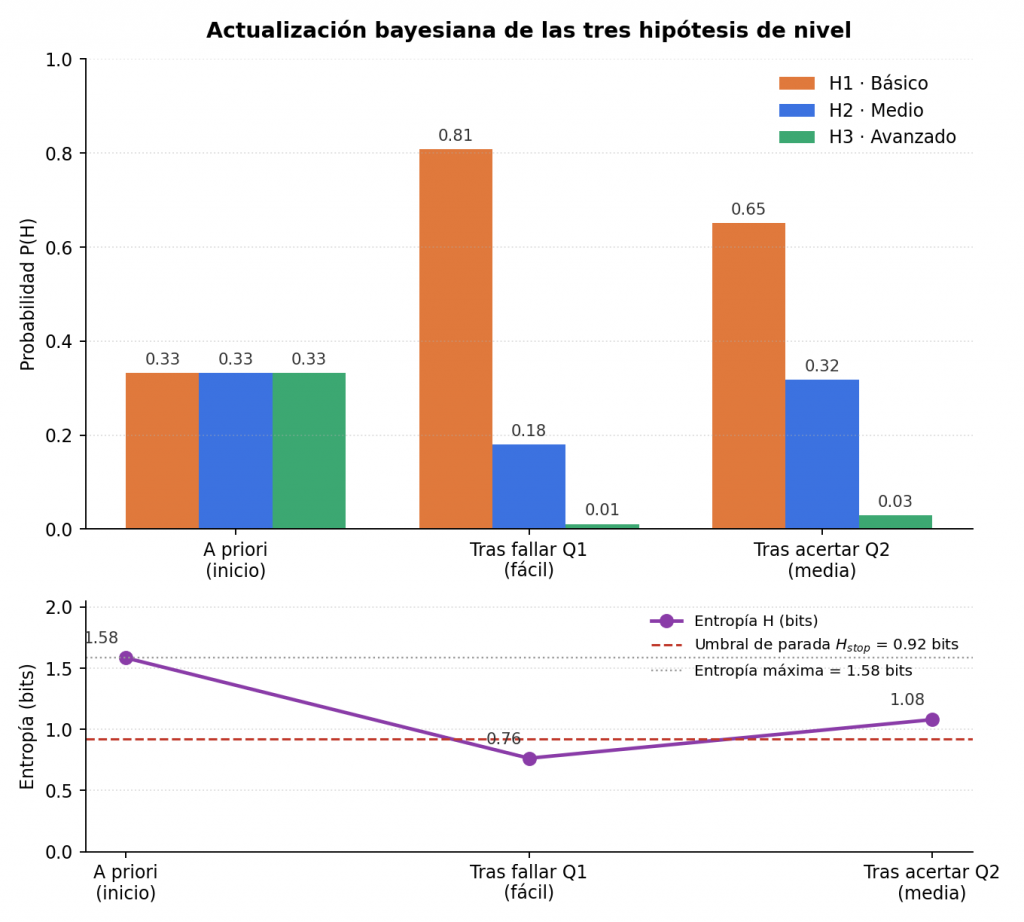
El siguiente ejemplo aplica el mecanismo a un caso concreto. Se parte de tres hipótesis con su habilidad ya fijada: H1 (θ₁ = −2, nivel básico), H2 (θ₂ = 0, nivel medio) y H3 (θ₃ = +2, nivel avanzado). El estado del alumno se representa como un vector de probabilidad P = (P(H1), P(H2), P(H3)), con un valor para cada hipótesis (el nivel al que pertenece) en ese orden y que siempre suma 1; al principio, sin ninguna respuesta todavía, ese vector es una probabilidad a priori uniforme, P = (0,33; 0,33; 0,33). Cada pregunta tiene además una dificultad b, en la misma escala que θ, que se explica con detalle en la sección siguiente: por ahora basta con saber que b = −1 corresponde a una pregunta fácil y b = 0 a una pregunta de dificultad media.
- El alumno falla una pregunta fácil (dificultad b = −1). La verosimilitud de fallar es alta bajo H1 y baja bajo H3, así que el vector de probabilidad se desplaza a P = (0,81; 0,18; 0,01): la probabilidad de H1 sube a 0,81, y las de H2 y H3 bajan a 0,18 y 0,01.
- El alumno acierta la siguiente pregunta, de dificultad media (b = 0). El vector pasa a P = (0,65; 0,32; 0,03): la probabilidad de H1 baja ligeramente y la de H2 sube, porque acertar una pregunta de dificultad media es más compatible con un nivel medio que con uno básico.
La figura 1 muestra esa evolución junto con la entropía de cada paso (concepto que se explica en la sección siguiente). Entre el segundo y el tercer paso, la incertidumbre aumenta en lugar de disminuir, porque el acierto en una pregunta media reparte de nuevo la probabilidad entre H1 y H2. Se trata de un comportamiento correcto del modelo, no de un error: cada respuesta aporta la evidencia que aporta y no siempre reduce la incertidumbre. Este ejemplo se limita a dos preguntas y, como se explica en el criterio de finalización más adelante, una implementación real no daría por buena la convergencia solo por cruzar los umbrales de entropía y confianza, sino que exige además un número mínimo de preguntas respondidas.
Este cálculo se repite tras cada respuesta, de manera que la creencia sobre el alumno nunca queda congelada. Si un alumno empieza fallando, pero después encadena varios aciertos, el sistema revisa su estimación y se aleja del diagnóstico inicial: no existe un bloqueo irreversible en una categoría equivocada, algo que sí puede ocurrir en sistemas más simples que solo suben la dificultad tras un acierto y la bajan tras un fallo.
El modelo de respuesta al ítem y la dificultad de las preguntas
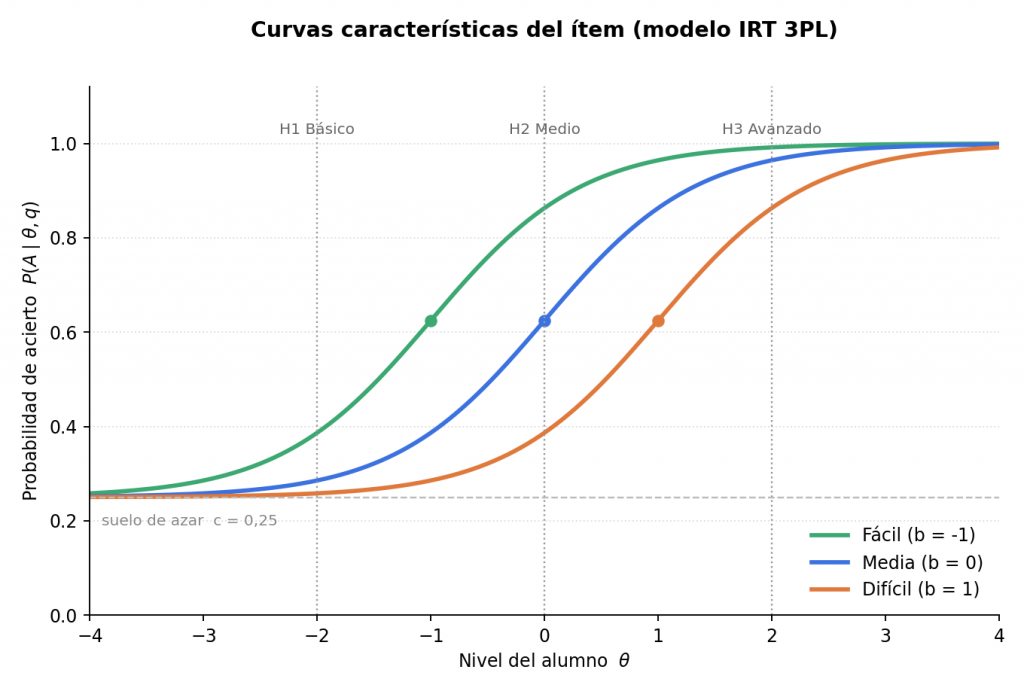
La verosimilitud \(P(r \mid H_i)\) que exige el teorema de Bayes no puede inventarse pregunta a pregunta y hace falta un modelo que relacione el nivel del alumno con la probabilidad de acertar una pregunta de una dificultad determinada. Esta metodología usa para ello la teoría de respuesta al ítem (TRI o, en inglés, IRT), en concreto el modelo logístico de tres parámetros (3PL), ya empleado en evaluación educativa desde los trabajos de Birnbaum en los años sesenta:
$$P(A \mid \theta, q) = c_q + (1 – c_q) \cdot \frac{1}{1 + e^{-a(\theta – b_q)}}$$
El significado de cada parámetro es el siguiente.
- θ es el nivel del alumno en la hipótesis que se está evaluando.
- \(b_q\) es la dificultad de la pregunta q: el punto en el que la probabilidad de acierto (descontado el azar) llega al 50 %.
- \(a\) es la discriminación: la pendiente de la curva. Cuanto mayor es \(a\), más bruscamente distingue la pregunta entre un alumno justo por debajo y justo por encima de su dificultad.
- \(c_q\) es el suelo de azar: la probabilidad mínima de acertar sin saber nada, que depende del número de opciones (0,25 en una pregunta de cuatro opciones, 0,5 en un verdadero/falso, 0 en una respuesta numérica abierta).
La figura 2 dibuja esa curva para tres preguntas de dificultad fácil, media y difícil, con a = 1,5 y c = 0,25, los valores por defecto que propone el protocolo. Se observa por qué una pregunta fácil es poco útil para un alumno avanzado (su probabilidad de acierto ya está pegada a 1) y por qué la zona más informativa de cada curva es la que rodea su propia dificultad, donde el resultado todavía podría ser acierto o fallo.
Estos valores de a, b y c no proceden de una calibración empírica con miles de respuestas reales, como ocurriría en un banco de ítems de una prueba estandarizada. Se generan a partir de valores por defecto respaldados por la literatura en TRI (Birnbaum, 1968; van der Linden y Hambleton, 1997), con a = 1,5 como punto de partida razonable, y de la estructura de cada pregunta. Es una limitación reconocida de manera explícita en la documentación técnica: son estimaciones a priori, útiles para poner en marcha el sistema, pero no medidas contrastadas con una muestra real de alumnado.
La entropía de Shannon como medida de incertidumbre
En este contexto, la incertidumbre no se refiere a una duda genérica, sino al grado en que la probabilidad sobre el nivel del alumno sigue repartida entre varias hipótesis. Si, tras algunas respuestas, las hipótesis H1, H2 y H3 tienen probabilidades parecidas, el sistema todavía no puede inclinarse con claridad por un diagnóstico. En cambio, si una de ellas concentra casi toda la probabilidad, la incertidumbre es baja, porque el estado del alumno está mucho mejor definido.
El sistema necesita cuantificar esa incertidumbre para tomar dos decisiones concretas a lo largo de la prueba. Por un lado, para decidir cuándo dejar de preguntar, es decir, cuándo la creencia sobre el nivel del alumno ya es lo bastante firme como para dar el diagnóstico por bueno, algo que se desarrolla en el criterio de finalización más adelante. Por otro, para comparar qué pregunta, de entre las disponibles, reduciría más esa incertidumbre si se planteara, que es el criterio de selección que se explica en la sección siguiente. La magnitud elegida para cuantificarla es la entropía de Shannon, tomada directamente de la teoría de la información.
$$H(p) = -\sum_{i} p_i \log_2 p_i$$
Se mide en bits. Con tres hipótesis equiprobables (0,33 cada una), la entropía es máxima: \(H = \log_2 3 \approx 1{,}58\) bits, la ignorancia total del punto de partida de la figura 1. Cuando una hipótesis concentra casi toda la probabilidad, la entropía cae hacia 0: por ejemplo, una distribución (0,95; 0,04; 0,01) tiene una entropía de solo 0,32 bits.
La entropía es preferible a mirar simplemente «cuál es la hipótesis con más probabilidad», porque distingue matices que un máximo por sí solo no recoge: dos distribuciones pueden compartir la misma hipótesis ganadora con la misma probabilidad y, sin embargo, repartir el resto de un modo muy distinto, lo que la entropía sí refleja. Por ejemplo, P = (0,80; 0,15; 0,05) y P = (0,80; 0,19; 0,01) comparten la misma hipótesis ganadora con la misma probabilidad (0,80), así que mirar solo el máximo sugeriría el mismo grado de confianza en ambos casos. Sus entropías, sin embargo, son distintas: 0,88 bits y 0,78 bits respectivamente, porque en la segunda distribución el 20 % restante está mucho más concentrado en una sola hipótesis (0,19 frente a 0,01) que en la primera (0,15 frente a 0,05). En la práctica, eso significa que la entropía captura matices de la distribución que el máximo no recoge, y por eso es la magnitud con la que el sistema mide la incertidumbre y valora cuánto la reduciría cada pregunta. Para cerrar el diagnóstico, en cambio, lo que decide es la confianza mínima de la hipótesis ganadora junto con el mínimo de preguntas: cuando el umbral de entropía se deriva de esa misma confianza, la condición de confianza ya implica la de entropía, de modo que comprobar ambas es inofensivo, pero no añade exigencia.
Selección de preguntas por ganancia esperada de información
Aquí aparece uno de los puntos donde esta metodología se aparta de la práctica habitual en los test adaptativos informatizados (CAT, por sus siglas en inglés). El criterio para elegir la siguiente pregunta es la ganancia esperada de información, es decir, cuánto se espera que baje la entropía si se hace esa pregunta, promediando los dos resultados posibles:
$$IG(q) = H(P) – \big[P(A)\, H(P_{post,A}) + P(F)\, H(P_{post,F})\big]$$
donde \(P(A)\) y \(P(F)\) son las probabilidades esperadas de acierto y fallo bajo la distribución actual, y \(P_{post,A}\), \(P_{post,F}\) son las probabilidades a posteriori que resultarían en cada caso. El sistema calcula esta ganancia para todas las preguntas disponibles y elige la que promete reducir más la incertidumbre, sea cual sea la respuesta.
El criterio dominante en los CAT clásicos no es este, sino la función de información del ítem (FII), basada en la información de Fisher:
$$I_q(\theta) = \frac{[P'(\theta)]^2}{P(\theta)\,(1-P(\theta))}$$
La FII mide cuánta información aporta una pregunta en un punto concreto de la escala continua de habilidad θ (por ejemplo, θ = −1,5 podría corresponder a un alumno con dificultades notables, θ = 0 a uno de nivel medio y θ = +1,5 a uno con un dominio alto, pero también son válidos valores intermedios como θ = 0,7, a diferencia de las tres hipótesis discretas que maneja el enfoque bayesiano de este trabajo). Para evaluarla, el sistema clásico reduce todo lo que sabe del alumno a un único número: la estimación puntual θ̂, calculada habitualmente por máxima verosimilitud a partir de las respuestas dadas hasta ese momento. Es decir, mientras que el enfoque bayesiano de este artículo mantiene un vector completo de probabilidades sobre las hipótesis de nivel, por ejemplo P = (P(H1), P(H2), P(H3)), el CAT clásico colapsa esa misma información en un único valor θ̂ sobre la recta real (por ejemplo, θ̂ = 0,4) y evalúa la FII de cada pregunta candidata justo en ese punto, no en el resto de valores que θ podría tomar. El criterio bayesiano descrito aquí es preferible cuando el estado del alumno se representa como una distribución completa y no como ese punto único, por dos razones: usa toda la distribución en vez de forzar un colapso a un único valor antes de decidir, si, por ejemplo, la probabilidad está repartida casi por igual entre H1 y H2, θ̂ caerá en un punto intermedio que no representa bien a ningún alumno real, y la FII evaluada justo ahí puede recomendar una pregunta que no sea útil para distinguir entre esas dos hipótesis; y no exige que las hipótesis estén ordenadas en una única escala, lo que permite aplicarlo también a diagnósticos de errores conceptuales sin relación de orden entre sí. Ahora bien, nominal no significa siempre excluyente: si los errores son realmente alternativos, puede usarse una hipótesis por error; pero si varios errores pueden coexistir, el modelo correcto pasa a ser multifactorial o por perfiles completos, y la evidencia ideal no es solo la probabilidad de acierto, sino también qué distractor elige el alumno. El propio protocolo detalla estas variantes cuando las hipótesis no tienen orden.
Cuando varias preguntas tienen una ganancia casi idéntica, algo frecuente cuando comparten dificultad y número de opciones, el sistema no elige siempre la misma: aplica una selección aleatoria ponderada que favorece la variedad de categorías, para evitar que dos sesiones distintas generen la misma secuencia de preguntas.
Criterio de finalización y umbral de entropía
La prueba termina cuando se cumple alguna de estas dos condiciones: se alcanza una convergencia fiable, o se agota el número de preguntas disponibles sin haberla alcanzado. La convergencia fiable exige tres condiciones a la vez, no solo dos: haber respondido un número mínimo de preguntas, que la entropía caiga por debajo de un umbral \(H_{stop}\), y que la hipótesis más probable supere una confianza mínima \(p_{min}\).
El número mínimo de preguntas evita aceptar como firme una estimación basada en muy poca evidencia: antes de alcanzarlo, el sistema sigue preguntando aunque la entropía ya haya cruzado el umbral y una hipótesis ya supere la confianza mínima. De hecho, en el ejemplo numérico de la sección anterior esto ya ocurre tras la primera respuesta: al fallar Q1 la entropía baja a 0,764 bits (por debajo del umbral de 0,92 que se calcula más abajo) y la probabilidad de H1 sube a 0,81 (por encima de 0,80); sin un mínimo de preguntas exigido, el sistema daría ya por bueno un diagnóstico de nivel básico con una sola respuesta. Ese mínimo depende del diseño del recurso: en una etapa breve de práctica puede bastar con 4 preguntas; en un test diagnóstico más amplio puede exigirse un mínimo mayor, por ejemplo 8, junto con una cobertura mínima de dificultades o categorías.
La confianza mínima \(p_{min}\) tampoco es un valor universal: el protocolo puede trabajar con 0,80, 0,85 o cualquier otro valor según el tipo de recurso, la longitud esperada de la prueba, el número de hipótesis y el grado de prudencia deseado. Lo importante es que el umbral de entropía se derive de la confianza mínima elegida y del número de hipótesis consideradas:
$$H_{stop} = -p_{min} \log_2 p_{min} – (1-p_{min}) \log_2!\left(\frac{1-p_{min}}{n-1}\right)$$
Con \(p_{min}=0{,}80\) y n = 3 hipótesis, ese umbral vale aproximadamente 0,92 bits, la línea roja discontinua de la figura 1.
Se exige, además, que entropía y confianza mínima se cumplan juntas y no una sola de ellas, porque no equivalen a lo mismo: una distribución puede tener entropía baja sin que la hipótesis ganadora llegue a esa confianza mínima, si parte de las hipótesis quedan prácticamente descartadas, pero todavía existe una segunda hipótesis con una probabilidad apreciable, en vez de que el resto de la probabilidad se reparta por igual entre todas las demás (de hecho, la condición de confianza implica la de entropía cuando el umbral se deriva de ella; lo que realmente decide el cierre son el mínimo de preguntas y la confianza mínima).
Si el test termina sin cumplir las tres condiciones, el informe final lo indica de forma explícita: el diagnóstico se presenta como provisional, en lugar de ofrecer una falsa seguridad.
Comprobaciones de fiabilidad sin datos empíricos
Como los parámetros del modelo son estimaciones a priori (sección anterior), la metodología incorpora dos comprobaciones que permiten detectar cuándo el resultado no merece confianza, sin necesitar una muestra empírica de alumnado. Es, junto con el criterio de selección por entropía, el segundo punto donde este enfoque se separa de una implementación ingenua de un test adaptativo.
El índice person-fit (\(l_z\)). Detecta si el patrón de respuestas de un alumno concreto es coherente con el nivel que el modelo le ha asignado. Compara la log-verosimilitud observada del patrón de respuestas con la que cabría esperar bajo ese nivel, y estandariza la diferencia:
$$l_z = \frac{l_0 – E[l_0]}{\sqrt{\mathrm{Var}[l_0]}}$$
Bajo el modelo, \(l_z\) se distribuye aproximadamente como una normal estándar. Valores muy negativos (orientativamente \(l_z < -2\)) señalan un patrón improbable bajo el nivel estimado, típicamente acertar preguntas difíciles y fallar las fáciles, o responder al azar, lo que implica que el diagnóstico, aunque el sistema lo presente como «seguro», puede no ser fiable para ese alumno en concreto. La entropía dice cuán segura está la creencia del modelo; el person-fit dice si esa seguridad está justificada por el propio patrón de respuestas.
La validación por simulación (Monte Carlo). Responde a una pregunta distinta: no si un alumno concreto encaja en el modelo, sino si el banco de preguntas en su conjunto distingue bien los niveles. El procedimiento genera alumnos sintéticos situados exactamente en el θ de cada hipótesis, les hace responder de forma simulada (con la misma probabilidad de acierto que marca la curva IRT) y construye una matriz de confusión que compara el nivel real con el nivel diagnosticado. Es una comprobación de la coherencia interna del diseño, calculable antes de aplicar el test a nadie, aunque con un límite importante: los alumnos simulados se generan con el mismo modelo que después los clasifica, así que mide si el diseño discrimina los niveles, no si los parámetros reflejan la realidad de un aula concreta.
Diagnóstico multidimensional por habilidades
En uno de los recursos construidos con esta metodología, un laboratorio de combinatoria, el sistema no se limita a estimar un nivel general por tipo de problema. Mantiene, en paralelo, una distribución bayesiana independiente por cada habilidad transversal implicada (por ejemplo, la lectura del enunciado frente a los pasos de resolución), y todas se actualizan con la misma respuesta del alumno: el resultado global modifica la creencia sobre el nivel, y cada componente de la respuesta modifica la creencia sobre su dimensión correspondiente. Así, la estimación de nivel indica qué tipo de problema conviene practicar, y el diagnóstico por dimensión indica qué paso concreto conviene explicar o reforzar. Este punto no es un adorno técnico: cuando varias dificultades pueden coexistir, separarlas por dimensiones o por perfiles es la forma correcta de no forzar como excluyentes errores que en realidad pueden darse a la vez.
Cuando el ejercicio se corrige por pasos, la respuesta no es únicamente un acierto o fallo: se resume en una puntuación s entre 0 y 1, y la verosimilitud se interpola entre la de acierto y la de fallo, de modo que una respuesta parcialmente correcta desplaza la creencia en proporción a su calidad.
Diagnóstico inicial y refuerzo dirigido en la práctica prolongada
El mismo razonamiento se aplica, por ejemplo, en un itinerario de aprendizaje sobre ecuaciones de primer grado construido con este protocolo, donde decide cuándo dar por superada una etapa y cuándo insertar una tarjeta de refuerzo tras errores repetidos. En estos recursos de práctica prolongada, el diagnóstico no persigue solo un instante final, sino que la selección de preguntas se organiza en dos fases sucesivas, con un objetivo distinto cada una.
Fase diagnóstica inicial. Mientras existan categorías o tipos de problema con muy pocos intentos todavía (por ejemplo, menos de dos), el sistema los prioriza, para evitar sacar conclusiones de una muestra demasiado pequeña. Dentro de esas categorías, elige la pregunta con mayor ganancia esperada de información, igual que en la evaluación descrita en las secciones anteriores.
Fase de refuerzo. Una vez que todas las categorías tienen ya una muestra mínima, el sistema deja de repartir preguntas por igual entre ellas y prioriza la categoría con menor dominio estimado. Además, la pregunta concreta ya no se elige solo por su ganancia de información: se combina con una medida de cercanía a la dificultad del alumno, mediante una puntuación de utilidad del tipo:
$$\text{utilidad} = \alpha \cdot IG_{normalizada} + (1-\alpha) \cdot \text{ajuste de dificultad}$$
con α entre 0,6 y 0,7. Esta separación en dos fases evita un uso excesivo de la entropía: la entropía responde a «dónde tengo más incertidumbre», pero no siempre a «qué necesita practicar más el alumno», y en un recurso de refuerzo interesan ambas preguntas. Para el alumno, esto se traduce en que la práctica no se convierte en una sucesión de ejercicios cada vez más difíciles: una vez detectado en qué tipo de problema falla más, el sistema le da más ejercicios de ese tipo, pero ajustados a una dificultad que todavía puede abordar, en vez de plantarle directamente los más exigentes solo porque son los más informativos para el diagnóstico.
En un recurso de práctica, el alumno aprende mientras practica, y la actualización bayesiana pura da el mismo peso a la primera respuesta que a la última, de modo que la estimación puede quedarse anclada en un estado que el alumno ya ha superado. Para evitarlo, la metodología incorpora un olvido exponencial: en la fase de refuerzo, la creencia acumulada se atenúa ligeramente antes de cada actualización (elevándola a una potencia λ = 0,95 y renormalizando), de modo que la respuesta de hace k ejercicios pesa λᵏ y el sistema recuerda de forma efectiva las últimas ~20 respuestas. Las recientes pesan más que las antiguas y la estimación sigue al alumno cuando mejora. Durante el diagnóstico inicial no se aplica (λ = 1), para no distorsionar el informe inicial. Es la versión mínima de los modelos de transición tipo Bayesian Knowledge Tracing (Corbett y Anderson, 1995), y el laboratorio de combinatoria citado arriba lo implementa.
Diferencias respecto a otros recursos adaptativos
La siguiente tabla resume los puntos en los que esta metodología se aparta de dos referencias habituales: los test adaptativos informatizados (CAT) clásicos de la psicometría, y las plataformas comerciales de aprendizaje adaptativo apoyadas en modelos entrenados con datos masivos de estudiantes.
| Aspecto | CAT clásico / plataformas con big data | Esta metodología bayesiana |
|---|---|---|
| Estado del alumno | Un valor puntual θ̂ tras cada respuesta. | Una distribución de probabilidad completa sobre varias hipótesis. |
| Criterio de selección | Función de información del ítem (Fisher), evaluada en θ̂. | Ganancia esperada de información (reducción de entropía) sobre toda la distribución. |
| Calibración de las preguntas | Requiere datos de una muestra amplia de alumnado real. | Valores a priori razonables, basados en valores de referencia ya publicados en estudios previos de TRI y en la estructura de cada pregunta. |
| Control de fiabilidad | Suele depender de validaciones estadísticas externas con datos reales. | Person-fit (\(l_z\)) y validación por simulación Monte Carlo, calculables sin datos empíricos. |
| Alcance del modelo | Pensado sobre todo para evaluación. | Protocolo único aplicable a evaluación, itinerarios, práctica, refuerzo y recomendación. |
| Autoría | Requiere una plataforma o un equipo de psicometría. | Protocolo documentado y portable, ejecutable por una IA a partir de la especificación del propio docente; los recursos resultantes pueden funcionar enteramente en el navegador del alumno, sin servidores externos. |
| Resultado final | Puntuación o nivel. | Interpretación pedagógica: dominio, errores probables, recomendación y grado de firmeza del diagnóstico. |
La fila de autoría de la tabla anterior requiere una aclaración, porque es la que hace posible el resto de diferencias: el teorema de Bayes, la TRI y la entropía de Shannon no son ideas nuevas, tienen décadas de recorrido en psicometría. Lo que sí es más reciente es formalizarlos como un protocolo escrito, con reglas explícitas, pensado para que una inteligencia artificial genere un recurso completo (banco de preguntas, verosimilitudes, criterio de parada, informe final) a partir de la descripción de un tema, un curso y unos objetivos dados por el docente, sin exigir conocimientos de estadística ni acceso a una base de datos de respuestas de otros alumnos. Eso traslada una técnica hasta ahora reservada a grandes proveedores educativos al alcance de cualquier profesor que quiera construir su propio recurso a medida de un contenido concreto.
Límites de la metodología
Esta metodología no sustituye el criterio docente. Sus resultados deben interpretarse con prudencia cuando hay pocas preguntas disponibles, cuando el banco no está bien calibrado, cuando el alumno responde al azar o cuando la entropía final sigue siendo alta pese a haber terminado la prueba. El propio índice \(l_z\) tiene además una limitación técnica: es una aproximación asintótica, y con pocas preguntas su distribución se aleja de la normal, por lo que el umbral de −2 debe tomarse como una señal de cautela y no como una prueba formal. De la misma manera, la validación por simulación mide la coherencia interna del diseño bajo el propio modelo, no una validez empírica: para eso siguen haciendo falta datos reales de alumnado, algo que esta metodología no pretende sustituir.
Creación de recursos adaptativos con IA, dudas y profundización en la metodología
Los ejemplos citados en este artículo, un test adaptativo de cultura general, un itinerario sobre ecuaciones y un laboratorio de combinatoria, son implementaciones construidas con este protocolo. La implementación utilizando inteligencia artificial (vibe coding) junto con la documentación técnica completa (protocolo y fundamentos matemáticos) está disponible en la web de recursos educativos adaptativos del autor: https://jjdeharo.github.io/recursos-adaptativos/
Para resolver dudas concretas está disponible el asistente de IA, Fundamentos de los Sistemas Educativos Adaptativos Bayesianos, entrenado sobre el protocolo completo: https://notebooklm.google.com/notebook/1a4ee089-8c41-416e-ae43-28d24681bdc5.
Bibliografía recomendada
- Birnbaum, A. (1968). Some latent trait models and their use in inferring an examinee’s ability. En Lord, F. M. y Novick, M. R., Statistical Theories of Mental Test Scores. Addison-Wesley. Referencia fundacional del modelo logístico de tres parámetros.
- Rasch, G. (1960). Probabilistic Models for Some Intelligence and Attainment Tests. Danmarks Paedagogiske Institut (reeditado por University of Chicago Press, 1980). Modelo de dificultad de ítems.
- Cover, T. M. y Thomas, J. A. (2006). Elements of Information Theory (2.ª ed.). Wiley. Entropía de Shannon e información mutua.
- Corbett, A. T. y Anderson, J. R. (1995). Knowledge tracing: Modeling the acquisition of procedural knowledge. User Modeling and User-Adapted Interaction, 4(4), 253–278.
- van der Linden, W. J. y Hambleton, R. K. (Eds.) (1997). Handbook of Modern Item Response Theory. Springer. Referencia enciclopédica de modelos y aplicaciones de la TRI.
- van der Linden, W. J. y Glas, C. A. W. (Eds.) (2010). Elements of Adaptive Testing. Springer. Selección adaptativa de ítems e información.
- Drasgow, F., Levine, M. V. y Williams, E. A. (1985). Appropriateness measurement with polychotomous item response models and standardized indices. British Journal of Mathematical and Statistical Psychology, 38(1), 67-86. Índice estandarizado de ajuste de la persona ($l_z$).
- López Pina, J. A. (2026). Teoría de la Respuesta al Ítem: Fundamentos y modelos. Editum, Ediciones de la Universidad de Murcia. DOI: 10.6018/editum.3178. En español y de acceso abierto.
- Wainer, H. (Ed.) (2000). Computerized Adaptive Testing: A Primer (2.ª ed.). Lawrence Erlbaum. Fundamentos de la evaluación adaptativa.
- Gelman, A. et al. (2013). Bayesian Data Analysis (3.ª ed.). CRC Press. Inferencia bayesiana general.
Nota: Este artículo tiene nivel 4 en el Marco para la integración de la IA generativa.









Deja una respuesta